Generating a Large PDF from Website Contents - Merging PDF Files
Dynamically generate a PDF file for a CMS Website.
Table of Contents
Posts in this series
- Generating a Large PDF from Website Contents
- HTML to PDF, Bookmarks and Handling Empty Pages
- Merging PDF Files
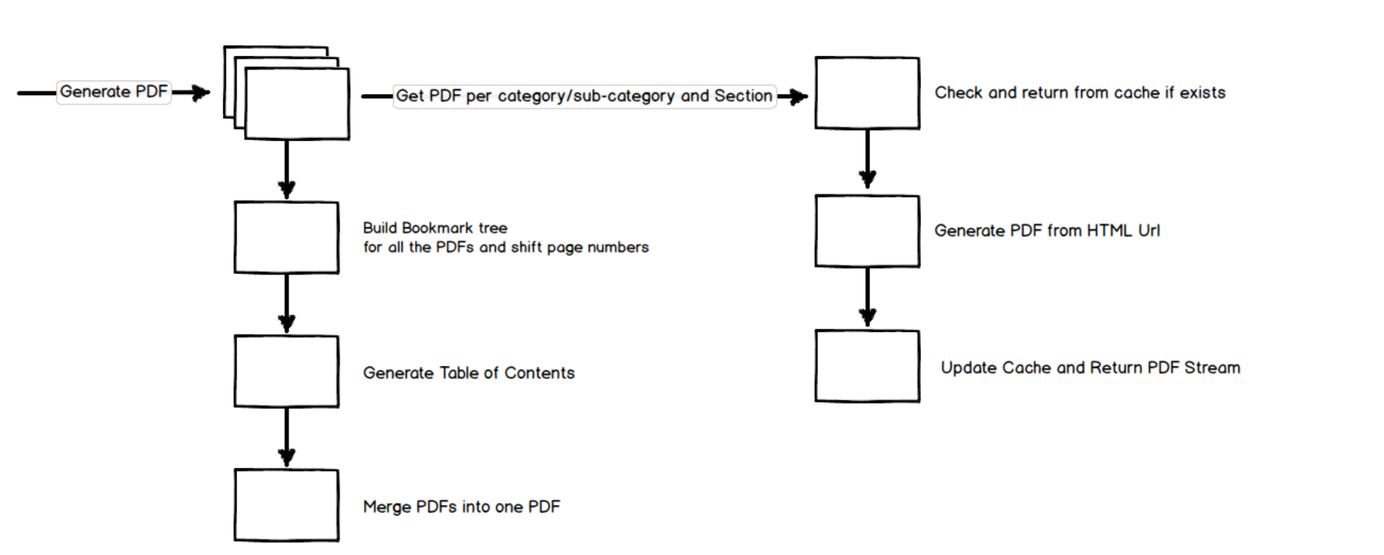
In the previous post, Generating a Large PDF from Website Contents - HTML to PDF, Bookmarks and Handling Empty Pages, we saw how to generate a PDF from HTML and add bookmarks to the generated PDF files. The PDF file generated is for an individual section which now needs to be merged to form a single PDF file. The individual PDF files contain the relevant content for the section and related bookmarks, which needs to be combined into a single PDF file.
One of the important things to keep intact when merging is the document hierarchy. The Sections, Sub-Categories, and Categories should align correctly so that the final bookmark tree and the Table of Contents appear correctly. It is best to maintain the list of individual PDF document streams in the same hierarchy as required. Since we know the required structure right from the UI, this can be easily achieved by using a data structure similar as shown below
public class DocumentSection
{
public MemoryStream PDFDocument {get; set;}
public List<DocumentSection> ChildSections {get; set;}
... // Any additional details that you need
}
The above structure allows us to maintain a tree-like structure of the document. The structure is the same as that is provided to the user to select the PDF options. I used the iTextSharp library to merge PDF documents. To interact with the PDF, we first need to create a PdfReader object from the stream. Using the SimpleBookmark class, we can get the existing bookmarks for the PDF.
var pdfReader = new PdfReader(stream);
ArrayList bookmarks = SimpleBookmark.GetBookmark(pdfReader);
iText representation of bookmarks is a bit complex. It represents them as an ArrayList of Hashtables. The Hashtable has keys like Action, Title, Page, Kids, etc. Kids property represents child bookmarks and is the same ArrayList type. Since it was hard to work with this structure, I created a wrapper class to interact easily with the bookmarks.
public class Bookmark
{
public Bookmark(
string title, string destinationType, int pageNumber,
float xLeft, float yTop, float zZoom)
{
Children = new List<Bookmark>();
Title = title;
PageNumber = pageNumber;
DestinationType = destinationType ?? "XYZ";
XLeft = xLeft;
YTop = yTop;
ZZoom = zZoom;
PageBreak = false;
}
... // Class properties for the constructor parameters
public ArrayList ToiTextBookmark()
{
ArrayList arrayList = new ArrayList
{
ToiTextBookmark(this),
};
return arrayList;
}
private Hashtable ToiTextBookmark(Bookmark bookmark)
{
var kids = new ArrayList();
var hashTable = new Hashtable
{
["Action"] = "GoTo",
["Title"] = bookmark.Title,
["Page"] = $@"{bookmark.PageNumber} {bookmark.DestinationType}
{bookmark.XLeft} {bookmark.YTop} {bookmark.ZZoom}",
["Kids"] = kids,
};
foreach (var childBookmark in bookmark.Children)
{
kids.Add(ToiTextBookmark(childBookmark));
}
return hashTable;
}
}
Recursively iterating through the list of DocumentSections, I add all the bookmarks to a root Bookmark class. The root bookmark class represents the full bookmark of the PDF file. The PageNumber is offset using a counter variable. The counter variable is incremented by the number of pages in each of PDF section (pdfReader.NumberOfPages) as it gets merged to the bookmark root. This ensures that the bookmark points to the correct bookmark page in the combined PDF file.
The individual documents are then merged by iterating through all the generated document sections. Once done we get the final PDF as a byte array which is returned to the user.
public byte[] MergeSections(List<DocumentSection> documentSections, Bookmark bookmarkRoot)
{
int pageNumber = 0;
using (var stream = new MemoryStream())
{
var document = new Document();
var pdfWriter = PdfWriter.GetInstance(document, stream);
document.Open();
var pdfContent = pdfWriter.DirectContent;
MergeSectionIntoDocument(documentSections, document, pdfContent, pdfWriter, pageNumber);
pdfWriter.Outlines = bookmarkRoot.ToiTextBookmark();
document.Close();
stream.Flush();
return stream.ToArray();
}
}
private void MergeSectionIntoDocument(
List<DocumentSection> documentSections,
Document document,
PdfContentByte pdfContent,
PdfWriter pdfWriter,
int pageNumber)
{
foreach (var documentSection in documentSections)
{
var stream = documentSection.DocumentStream;
stream.Position = 0;
var pdfReader = new PdfReader(stream);
for (var i = 1; i <= pdfReader.NumberOfPages; i++)
{
var page = pdfWriter.GetImportedPage(pdfReader, i);
document.SetPageSize(new iTextSharp.text.Rectangle(0.0F, 0.0F, page.Width, page.Height));
document.NewPage();
pageNumber++;
pdfContent.AddTemplate(page, 0, 0);
this.AddPageNumber(pdfContent, document, pageNumber);
}
if(documentSection.ChildSections.Any())
MergeSectionIntoDocument(documentSection.ChildSections, document, pdfContent, pdfWriter, pageNumber);
}
}
To generate a Table of Contents (ToC), we can use the root bookmark information. We need to manually create a PDF page, read the bookmark text and add links to the page with the required font and styling. iText provides API's to create custom PDF pages.
We are now able to generate a single PDF based on the website contents.

Rahul Nath Newsletter
Join the newsletter to receive the latest updates in your inbox.


{kind=link}