Left Align Your Code For Better Readability
Keeping you code aligned to the left makes it more easy to read and refactor.
Table of Contents
Aesthetics of code is as important as the code you write. Aligning is an important part that contributes to the overall aesthetics of code. The importance of code aesthetics struck me while on a recent project. Below are some the code samples that I came across in the project. Traversing this code base was painful to me as the code was all over the place.
// Bad Formatting
public class Account
{
public long Id { get; set; }
public string ClientId { get; set; }
public long ContactId { get; set; }
public string UserName { get; set; }
public string Name { get; set; }
public string Company { get; set; }
public string Address { get; set; }
public string BillingAddress { get; set; }
}
// Bad Formatting
public ConnectToServer(string username,
string password,
string server,
string port)
{
...
}
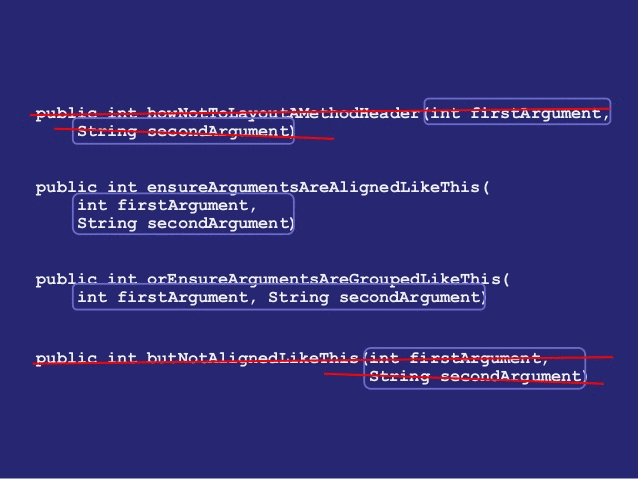
The code has too many alignment points that attract the eye which makes it hard to read in the first place. When in isolation this might still be fine to read, but with such a style across the code base, it soon becomes a pain for your eyes and your mind. When refactoring code, it becomes even harder as you need to put in the extra effort to make sure that this fancy alignment is maintained. Let's take a look at how even changing a property name (Company to CompanyName) or function name(ConnectToServer to Connect) will affect the current formatting.
// Renamed to CompanyName
public class Account
{
...
public string Name { get; set; }
public string CompanyName { get; set; }
public string Address { get; set; }
...
}
// Renamed to Connect
public Connect(string username,
string password,
string server,
string port)
{
...
}
As you can see above the formatting is now all over the place, and you need to format them into place manually. Again when in isolation this might seem like a few press of spacebar. But when the property/function that you rename is used in multiple places this soon becomes a problem. Such code formatting introduces maintenance overhead and soon falls out of place if something gets missed.
Better Ways To Format Code
Left aligning code is one of the key things that I try to follow always. Keeping the code aligned to the left makes it easier to read (assuming that you are programming in a language written from left to right). Since we read from left to right having most of the code aligned to the left means that you have more code visible. Left aligning also means that you would almost avoid the need to scroll the code editor when reading through the code horizontally.
Let's take a look how left aligning the above code will look like.
// Left Aligned
public class Account
{
public long Id { get; set; }
public string ClientId { get; set; }
public long ContactId { get; set; }
public string UserName { get; set; }
public string Name { get; set; }
public string Company { get; set; }
public string Address { get; set; }
public string BillingAddress { get; set; }
}
// Left Aligned Multiple Lines
public ConnectToServer(
string username,
string password,
string server,
string port)
{
...
}
// Left Aligned Single Line
public ConnectToServer(
string username, string password, string server, string port)
{
...
}
As you can see above left aligning makes it much easier to read and also reduces the number of alignment points. This is also refactoring friendly as there are no specific space patterns that need to be maintained. As for the parameters in a single line VS parameters in multiple lines (as above), I prefer the multi-line approach, as it keeps the code further aligned to the left and also reduces the chance of getting a horizontal scroll bar. You can use Column Guides to remind yourself to keep the code within the acceptable horizontal space.
Code formatting is an important aspect of coding. It is important that as a team you need to agree on some standard practices and find ways to stick to it. You can use styling tools, Code Reviews, etc. to make sure it does not get missed. It takes a while for any new practices to set in, but soon it will be of second nature and easy to follow.

Rahul Nath Newsletter
Join the newsletter to receive the latest updates in your inbox.


{kind=link}