Is Code Coverage a Lie?
This post reflects on how code coverage is seen today in the industry and on how it should actually be seen and interpreted so as to produce better and stable code.
Table of Contents
Code Coverage has been one of the important things that was always there on a daily build report and a number that managers were both interested and worried about. This has been the same for all projects that I had worked on, across various organizations. Various tools support measuring coverage and can be included as part of the build reports, which essentially indicates the percentage of source code that is covered by 'unit tests'. A higher percentage obviously indicates a better tested code and more stable one is what one would expect, as that would be the sole purpose of measuring this. But how far is this true? Is a code with higher test percentage one with lesser bugs? Does 100% indicate that it is totally bug free or is this a total wrong way of seeing that number?
What is Code Coverage and How is it Measured?
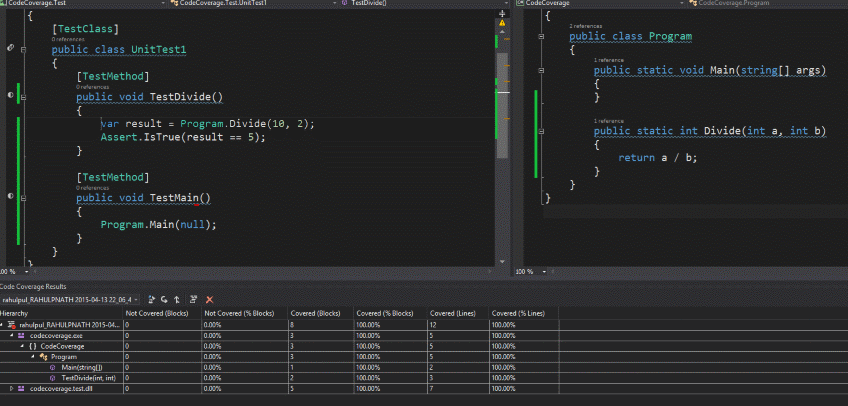
Code Coverage indicates the percentage of code that has been covered by at least one or more tests in your test suite. So if you have a simple function like the one shown below, which just divides two numbers and if you have one test that invokes that function, then you have a code coverage of 100%. When using Visual studio tests (as that is what I have used to depict the below one), code coverage is measured either based on blocks of code or based on lines of code.
- For the purposes of the tools, a block is defined as a sequence of instructions that have a single entry point and a single exit point. Exit points include branch instructions, a function call, a return instruction, or, for managed code, a throw instruction.
- For line-based coverage, the tools identify all of the blocks that make up a line and then use this information to determine the level of coverage for the line. If all of the blocks that make up the line are covered, then the tools report that the line is covered. If no blocks in the line are covered, then the tools report that the line is not covered. If some, but not all, of the blocks in the line are covered, then the tools report that the line is partially covered.
In the below case we have both 100% as there is only one line and one block and the test covers both. So should managers be happy with this code, since it has 100% coverage? Maybe they are, but ask the developers, they definitely are not, or probably they are if at the first place they wrote the tests for the sake of the report and since the managers are happy they too are. But is this what we should strive for - definitely not!
Trustworthy Unit Tests
Unit tests should be like a parachute - trustworthy. You are not going to jump out from an airplane with one that you know is faulty.
Having unit tests that are run once in a while or just for the build reports or when the manager is at your back, are a complete waste of time. A set of faulty tests do more harm than having none, as it might give wrong judgment of the code. From the above code you can definitely find that though the coverage is 100%, the code would simply fail when a value of 0 is passed for 'b', and it is highly likely that this would happen too.
If unit tests are written just to meet the code coverage number on a report, then I would rather fake the report than writing the tests
Unit Tests really make sense only when you write them following 'The Three Rules of TDD' or at the very least you have tests associated with every change that you make and also you make sure that we run the entire test suite before a check-in to make sure that you have broken nothing with your changes. Only when there is such 'trustworthiness' in the tests, does it make sense to have them in the first place and not for any number on a report.
How should we really see that number on the report?
Now that we have seen it is all about having trustworthy tests and not about reaching a targeted number for a report, what should we really use this Code coverage report data for?
- If you are less than 100% it clearly indicates that there are areas of your application that is not tested. You would really want to cross check if that is an intended miss or if there is something that is actually missing and add in some more tests to be covered better.
- When refactoring code, you can always make sure that you don't go back on the coverage number that you started with, so as to ensure that you have not introduced untested code into the system.
- When cleaning up tests a drop in the coverage number clearly indicates that you have actually removed some valid and non-redundant tests.
So the next time you add in a test, think why you are doing it. Is it for the report or for the application that is getting developed. Lets all strive to be really professional in what we are doing and not just hide behind some numbers. Let the number be seen for what it is - nothing less and nothing more!

Rahul Nath Newsletter
Join the newsletter to receive the latest updates in your inbox.

{kind=link}