Generating a Large PDF from Website Contents
Dynamically generate a PDF file for a CMS Website.
Table of Contents
Posts in this series
- Generating a Large PDF from Website Contents
- HTML to PDF, Bookmarks and Handling Empty Pages
- Merging PDF Files
At one of my recent clients, we had a requirement to generate a PDF dynamically based on the contents of the website. The website is a Content Management System (CMS) built on top of Umbraco. The content is grouped into different categories and sub-categories. Each category and sub-category had different sections/sub-sections under that. Some sections are optional for certain categories, and all of these are dynamic. In this post, I will walk through at high level the approach taken to solve the problem.
The user selects the categories/sub-categories and the sections that they wish to export as PDF. On submit, a PDF needs to be generated based on the website content.
public class Category
{
public string Name { get; set; }
public List<Section> Sections { get; set; }
public List<Category> SubCategory { get; set; }
}
public class Section
{
public string Name { get; set; }
public List<Section> SubSections { get; set; }
}
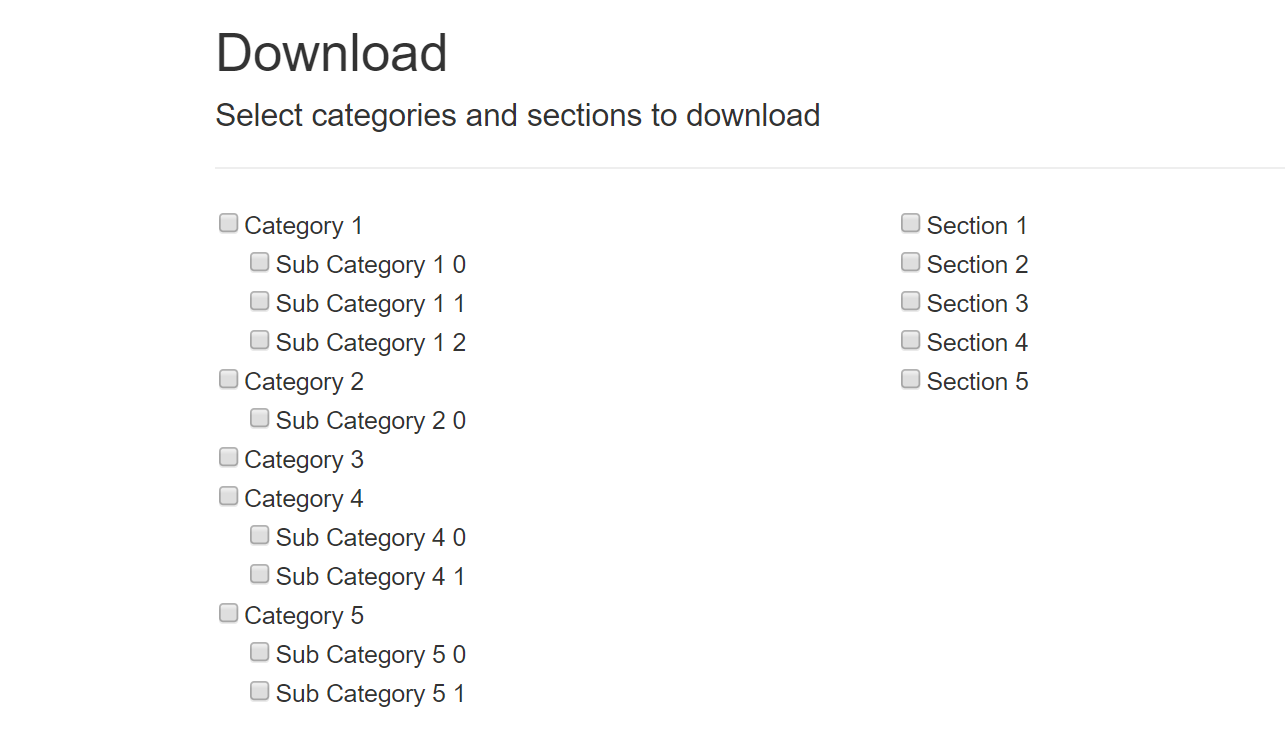
The actual site had one more level of options (say sub-sections), so you can imagine the number of possible combinations to generate the content. The site content was huge as well, and a PDF with all options selected would be around 4000-5000 pages. So creating the PDF every time some one clicks the button was out of the question. We had to cache the generated PDF's and serve them as the request comes in. But the challenge was how to manage the cache so that we can build up the PDF based on the options selected.
If you are using HTML to PDF libraries be aware that most of the libraries out there (Essential Object, EvoPDF etc.) does not work on Azure Web Apps. This is because of the sandbox restrictions on the applications irrespective of the Azure plan you are on. The preferred solution is to host the conversion code on a VM. If you find that an overhead (which it is) consider using the SAAS alternatives for converting HTML to PDF.
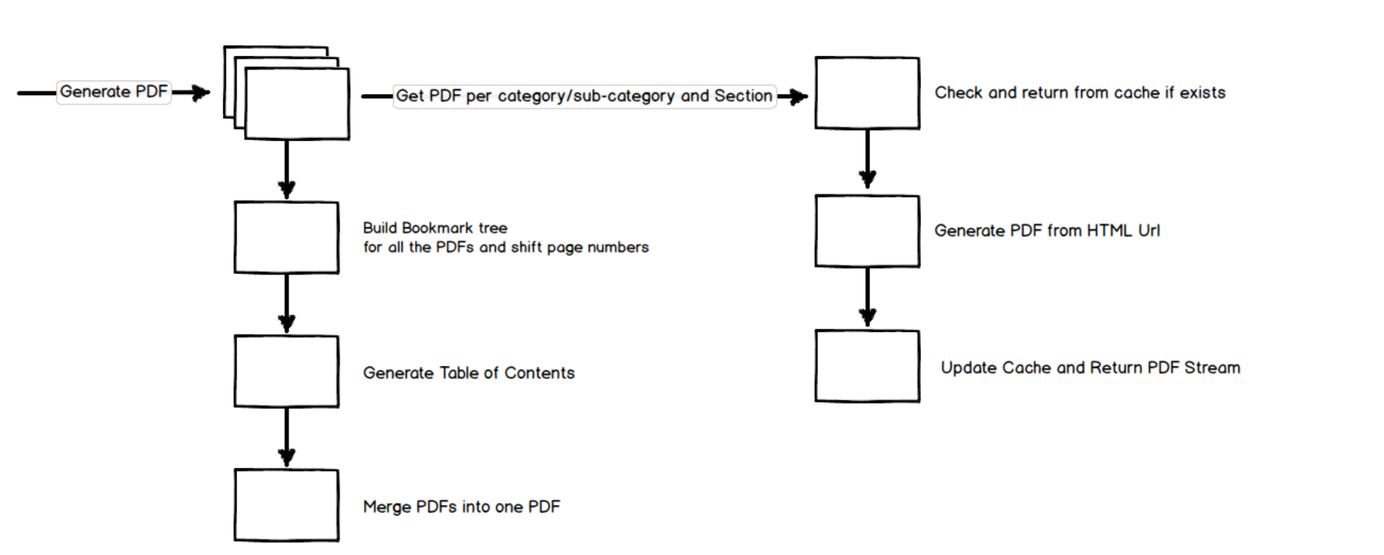
Below is the flow diagram of the complete process of generating the PDF as a request comes. The request specifies the categories/sub-categories along with the sections that need to be in the generated PDF.
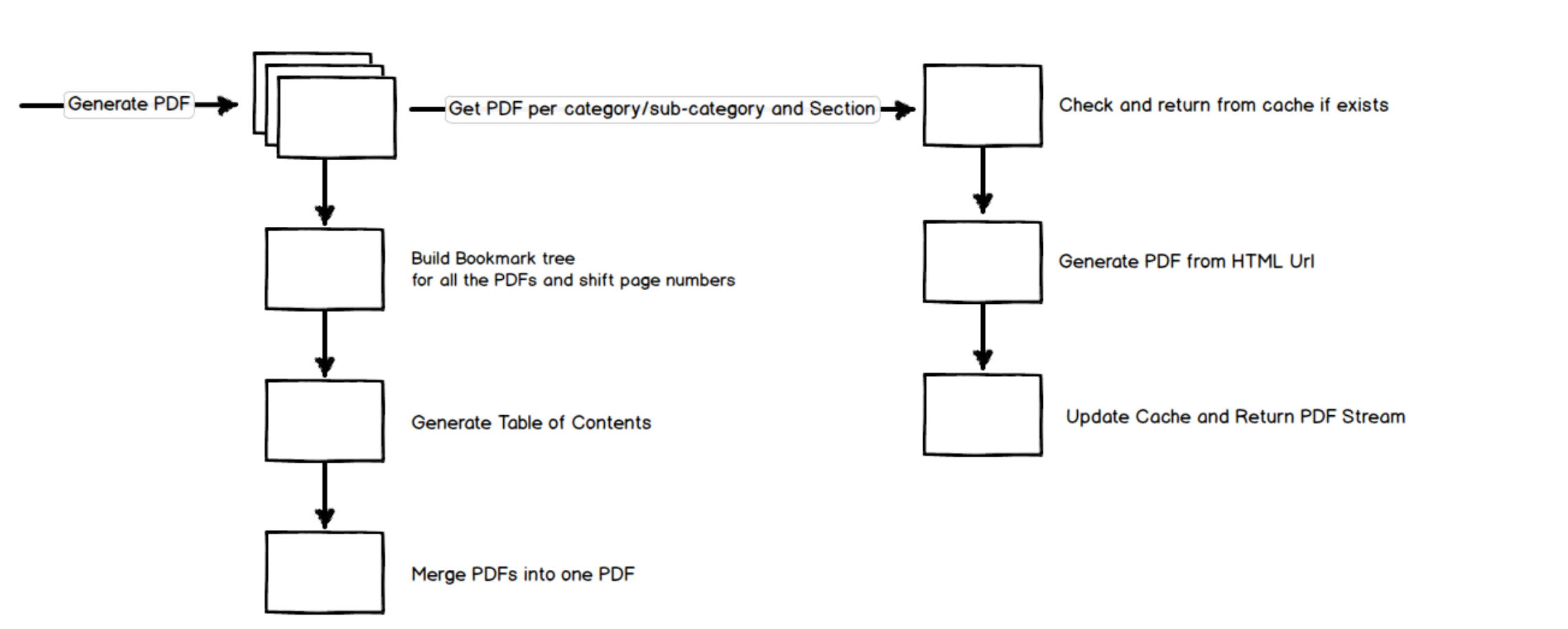
We decided to create a PDF file for each section per category/subcategory selection. Once all the sections are ready, all the PDF files will be merged into one. While merging we also build up the bookmark tree and the table of contents. Inserting the table of contents page at the start of the PDF requires pushing all the page numbers to match the new ones.
The PDF layout for individual sections per category/subcategory is in HTML. The application exposes endpoints for the HTML content for the different sections. We used Essential Object HTML to PDF Converter to convert the HTML to PDF files. Bookmarks for the associated section are embedded in HTML. While converting to PDF, the bookmarks get added to the PDF, which later gets merged into the full bookmark tree. The generated PDF file is cached for any new requests.
Since we have around forty categories/sub-categories, twelve section, and ten sub-sections, generating the full PDF take a while. So we generate the cache at fixed intervals and as required (when content is updated in the CMS). The above approach of generating PDF files has been working fine for us. Since the individual PDF sections are generated in isolation, it gives us the flexibility to scale the generation process as required. Combining the generated PDF files is often fast and can be cached at a different level as well to speed up the whole process.

Rahul Nath Newsletter
Join the newsletter to receive the latest updates in your inbox.


{kind=link}