
Using Repository Pattern for Abstracting Data Access from a Cache and Data Store
Table of Contents
A Repository abstracts the persistence logic from the core business logic and allows the data to be accessed as it would have been from an in-memory object collection.
Repository Pattern is useful when you want your domain objects(or entities) to be persistence ignorant but yet have the flexibility to map your data to the choice of your data store e.g. Sql Server, Oracle, NoSQL databases, cache etc. The physical model of the stored data might vary from store to store but not the logical model. So a repository plays the role of mapping a logical model to physical model and vice versa. ORM (Object Relational Mapping) tools like Entity Framework does help us to achieve this and we could make use of it wherever possible in building your domain specific repositories.
With large scale applications it is very common to have an external cache, to optimize repeated access to the data held in a data store. The repository is the ideal place to decide on populating, fetching and invalidating the cache. When building the repositories, we would not want to tightly couple ourselves with a specific cache provider or a data store provider like sql nor with any ORM tool like Entity Framework.
In this blog post we will be seeing how to keep our Repositories clean and separate from the actual providers and provide a persistence ignorant data access to your business layer.
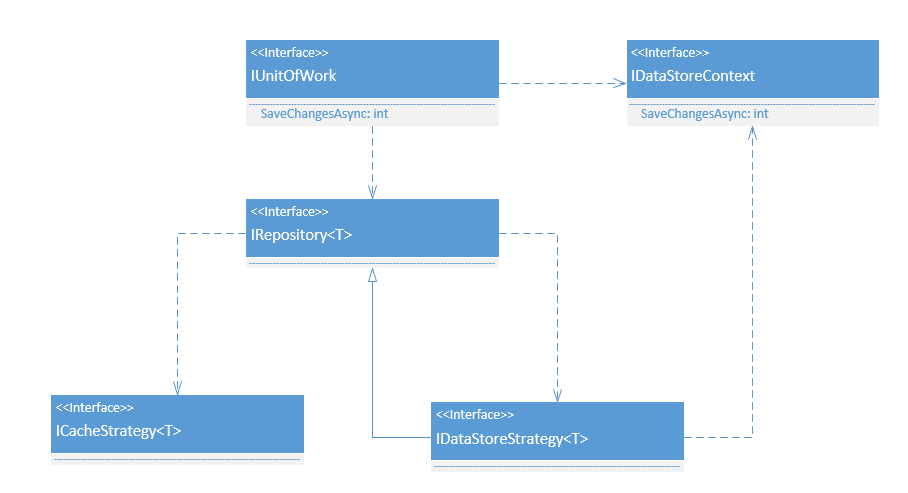
Creating the Repository
At the bare minimum a repository should be able to provide CRUD (Create Read Update Delete) options, for which we will have a generic interface defined and have implementation of which will be inherited from, for specific repositories.
public interface IRepository<T> where T : IIdentifiable
{
IEnumerable<T> GetAll();
T Delete(string id);
T GetById(string id);
T Insert(T entity);
T Update(T entity);
}
The implementation of this interface would need to perform following functionality:
- Decide on whether to get the data from cache or data store and keep the data consistent.
- Get/Modify the data from the cache
- Get/Modify the data from the data store.
Thinking of the SRP (Single Responsibility Principle), it is best to keep these responsibilities separate so that each of them can change independently without changing the other. For this we need to further introduce 2 more interfaces, one for getting the data from the cache and one for the data store. These 2 need not be the same, as a cache would mostly work on a key value pair combination and the one for the data store would need to have the same methods as supported by the repository (You could have them as the same too in case required). As for the repository, it depends on these 2 interface implementation (which we call strategies), to get the data - CacheStrategy or DataStoreStrategy.
public interface ICacheStrategy<T> where T : IIdentifiable
{
bool InsertOrUpdate(T entity);
T Get(string id);
bool Invalidate(string id);
}
public interface IDataStoreStrategy<T> : IRepository<T> where T : IIdentifiable
{
}
We see that above, for the Cache Strategy interface I have added a set of methods that acts on the key and the value, the entity itself. For the DataStore strategy, we have the same methods coming from the IRepository interface so that we can translate them all into corresponding querying format of their storage and return the data.
The Sql data store strategy implementation using Entity Framework would be like below, which will have a context provided to it, that it can use for performing the queries on sql database. Will see more on the context later below.(The interface implementations are omitted below to keep it simple). A cache strategy would also look something similar and would depend on the caching provider that you use.
public class SqlDataStoreStrategy<T> : IDataStoreStrategy<T>
where T : class, IIdentifiable
{
protected readonly SqlDataStoreContext dataContext;
protected readonly IDbSet<T> dbSet;
public SqlDataStoreStrategy(IDataStoreContext dataContext)
{
// Since this is a specific implementation for Sql it does know about the existence of SqlDataStoreContext
this.dataContext = dataContext as SqlDataStoreContext;
this.dbSet = this.dataContext.Set<T>();
}
}
The Generic repository implementation will use these strategies to return the data. For example, a Get, it will first look the cache and then the data store.
public class GenericRepository<T> : IRepository<T>
where T : IIdentifiable
{
protected ICacheStrategy<T> cacheStrategy;
protected IDataStoreStrategy<T> dataStoreStrategy;
public GenericRepository(ICacheStrategy<T> cacheStrategy, IDataStoreStrategy<T> dataStoreStrategy)
{
this.cacheStrategy = cacheStrategy;
this.dataStoreStrategy = dataStoreStrategy;
}
public T GetById(string id)
{
var item = this.cacheStrategy.Get(id);
if (item != null)
{
return item;
}
item = this.dataStoreStrategy.GetById(id);
this.cacheStrategy.InsertOrUpdate(item);
return item;
}
}
Creating Specific Repositories
There might be cases where we want to query on specific fields or combination of fields or do something that is specific for that repository. In these cases you can extend on to the repository methods. You would need to add a couple of classes for the new specific repository.
- Create a new repository interface and implement it.
- Create a new data store strategy interface which implements from the new repository interface and the base data store strategy interface and implement it.
- In case cache strategy needs an update update its interfaces too as like step 2
public interface IArticleRepository : IRepository<Article>
{
IEnumerable<Article> GetAllArticlesByCategory(string categoryName);
}
public interface IArticleDataStoreStrategy : IDataStoreStrategy<Article>, IArticleRepository
{
}
public class ArticleSqlDataStoreStrategy : SqlDataStoreStrategy<Article>, IArticleDataStoreStrategy
{
public ArticleSqlDataStoreStrategy(IDataStoreContext dataStoreContext) : base(dataStoreContext)
{
}
public IEnumerable<Article> GetAllArticlesByCategory(string categoryName)
{
// In case this is to return a large set of items then you can create a paged response and update the
// input also to take in the page number and number of articles in one page
return this.dbSet.Where(a => a.Category == categoryName).ToList();
}
}
Supporting Unit Of Work
There might be cases where we need to update against multiple repositories and have them all saved in one single transaction. UnitOfWork (UOW), is the common pattern that is used for this scenario, by passing around a context object that knows how to commit/save after a set of activities. For this support we have added the below set of interfaces.(Currently in this sample only the data store is supporting the transactions)
public interface IUnitOfWork : IDisposable
{
IRepository<Blog> BlogRepository { get; }
IArticleRepository ArticleRepository { get; }
Task<int> SaveChangesAsync();
}
public class UnitOfWork : IUnitOfWork
{
private IDataStoreContext dataStoreContext;
private readonly IUnityContainer container;
public IRepository<Blog> BlogRepository
{
get
{
// TODO : Use unity containers to generate the UnitOfwork so that to make sure that
// datacontext is a single instance in that instance of uow
return new GenericRepository<Blog>(
this.container.Resolve<ICacheStrategy<Blog>>(),
new SqlDataStoreStrategy<Blog>(this.dataStoreContext));
}
}
public IArticleRepository ArticleRepository
{
get
{
// TODO : Use unity containers to generate the UnitOfwork so that to make sure that
// datacontext is a single instance in that instance of uow
return new ArticleRepository(
this.container.Resolve<ICacheStrategy<Article>>(),
new ArticleSqlDataStoreStrategy(this.dataStoreContext));
}
}
public UnitOfWork(IDataStoreContext dataStoreContext, IUnityContainer container)
public async Task<int> SaveChangesAsync()
{
return await this.dataStoreContext.SaveChangesAsync();
}
}
The DataStoreContext is what maintains the in memory representation of the changes that we make across the repositories and finally saves it to the data store on SaveChangesAsync. For Sql data store we make use of the DbContext provided by Entity Framework, which already implements the same method from our interface. If you see the above sql strategy code, this is the data context that we use to perform queries and updates.
public interface IDataStoreContext : IDisposable
{
Task<int> SaveChangesAsync();
}
public class SqlDataStoreContext : DbContext, IDataStoreContext
{
public DbSet<Blog> Blogs { get; set; }
public DbSet<Article> Articles { get; set; }
}
For a client to perform operation, it can get the repositories through the unit of work as shown below.
var article = unitOfWork.ArticleRepository.GetById("1");
article.Name = "New Name";
unitOfWork.SaveChangesAsync();
IQueryable on your Repositories
In the repository methods we return an IEnumerable and not an IQueryable, as we want all my querying logics to be contained inside the strategies that implement the real querying. We definitely do not want the querying logic to be there all across the client code accessing the repository, as that would make maintaining the code difficult. Also each of the strategies would have their own ways of querying and should be well abstracted by them. Otherwise all we end up having would be a leaky abstraction
By separating out the cache and data store strategies we have made it possible to change the providers for either of them without affecting any of the repository code. We could switch out the sql data store strategy and have a oracle strategy or a mongodb strategy and have that implement the specifics on how to retrieve the the data that we want. We would also have a specific IDataStoreContext implementation for the corresponding new data store.
You can find the code structure for this here. It only provides the interfaces and some mock implementations and does not connect to any data stores or cache providers. Hope this helps in architecting the repository pattern when dealing with multiple strategies to save. What are your thoughts on this?

Rahul Nath Newsletter
Join the newsletter to receive the latest updates in your inbox.


{kind=link}