
DynamoDB Zero-ETL Integration With Amazon OpenSearch Service
Let's learn how to set up the DynamoDB Zero ETL plugin for OpenSearch, a fully managed, no-code setup for ingesting data into Amazon OpenSearch Service.
Table of Contents
How do you do a full-text search on the data in your DynamoDB database?
The simple answer is...
... You don’t.
DynamoDB excels at fast key-value and document queries but isn’t built for complex full-text search, like ranking or relevance filtering.
Attempting this on DynamoDB leads to performance issues, higher costs, and extra development work.
This is where Amazon OpenSearch excels. It’s optimized for complex full-text search and analytics, offering capabilities like relevance scoring, autocomplete, and advanced filtering.
With DynamoDB’s Zero ETL integration, you can seamlessly index the data in Amazon DynamoDB into Amazon OpenSearch.
In this blog post, let's learn how to set up the DynamoDB zero-ETL integration with Amazon OpenSearch Service.
DynamoDB Plugin for OpenSearch Ingestion
The Amazon DynamoDB zero-ETL plugin for OpenSearch is a fully managed, no-code setup for ingesting data into Amazon OpenSearch Service.
You can use one or more DynamoDB tables as a source for the data ingestion
How does the DynamoDB Zero ETL Plugin Work?
The plugin uses a combination of the data export feature and the DynamoDB Streams feature to get the data in near real-time from DynmoDB into OpenSearch.
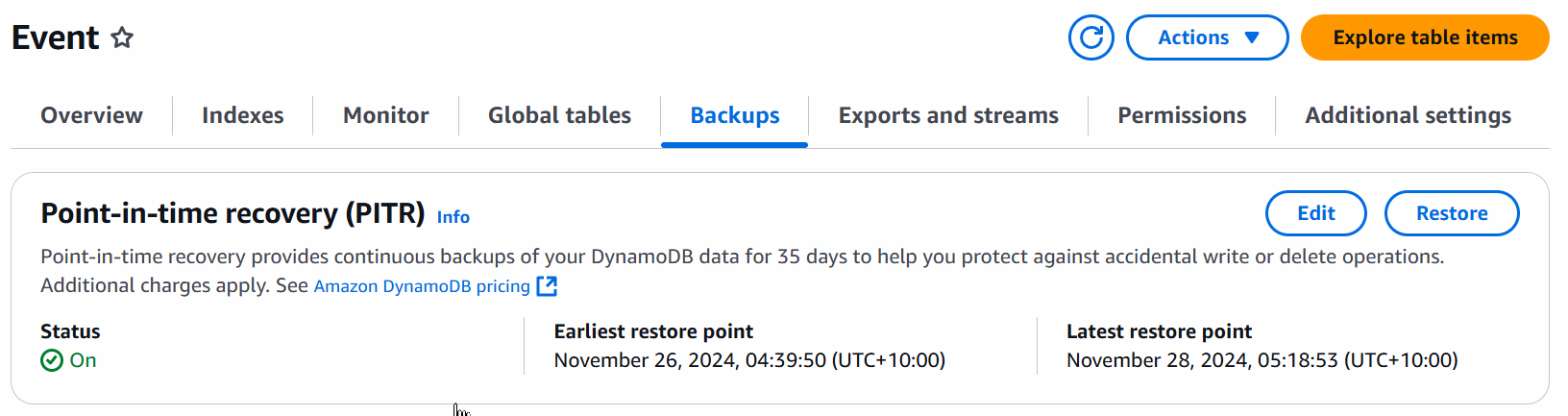
Before setting up the plugin, ensure that you have
- Turned on Point-In-Time Recovery (PITR) on DynamoDB Table
- Turned on DynamoDB Streams with 'New and old images' option
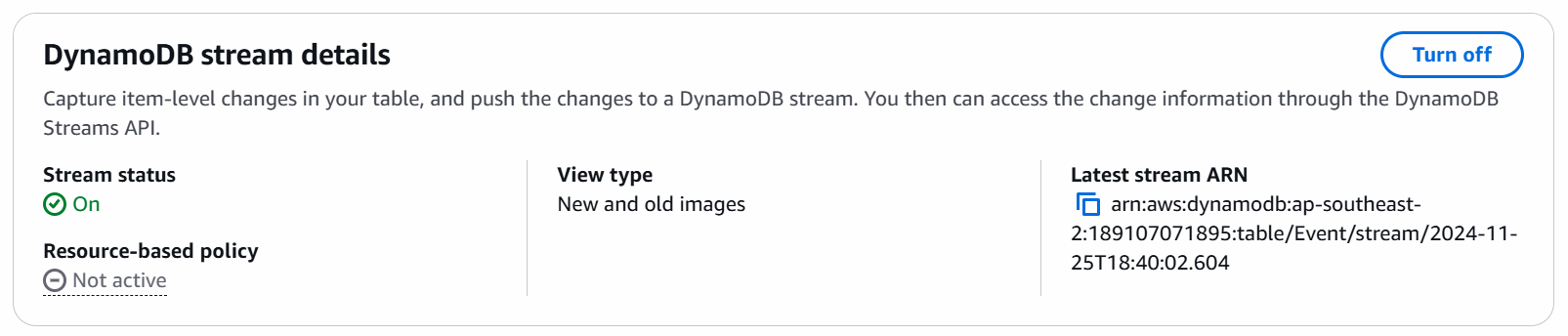
The plugin loads the initial data snapshot (using PITR) into an Amazon S3 bucket, which is then imported into OpenSearch. This is to get existing data in the table to OpenSearch.
For syncing real-time changes to items in the DynamoDB table, the plugin uses DynammoDB Streams to get notified of data changes and sync them to OpenSearch.
Setting Up DynamoDB Plugin For OpenSearch
To create a new ingestion pipeline, navigate to DynamoDB under AWS Console.
Under the Integration tab, you can create a new Integration and set up the Amazon OpenSearch data ingestion pipeline, as shown below.
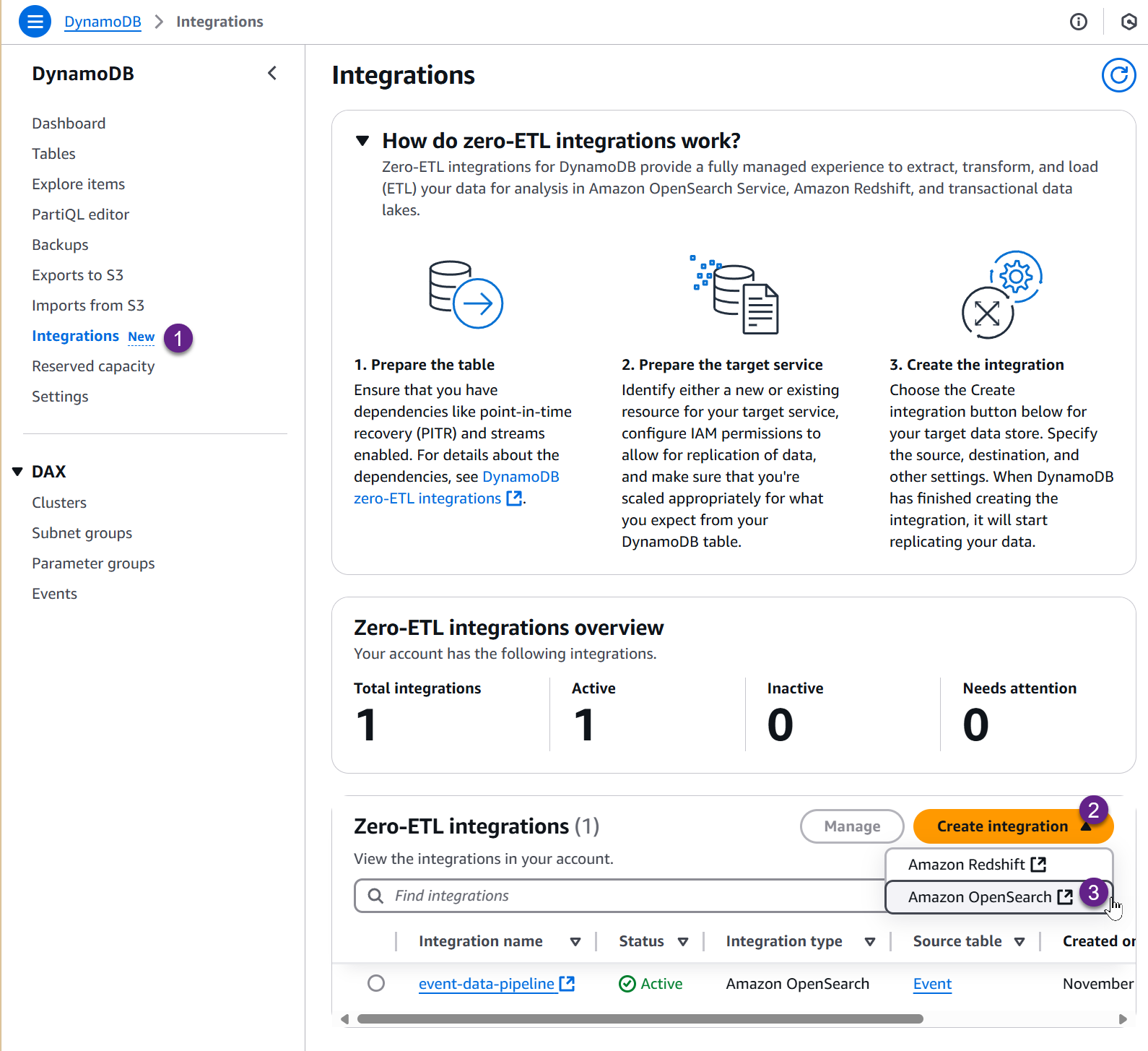
This prompts a new page where you can set up the ingestion pipeline details.
You must provide the pipeline name, capacity, and configuration in YAML or JSON format.
It also provides a default template schema that you can use as a starting point for the configuration.
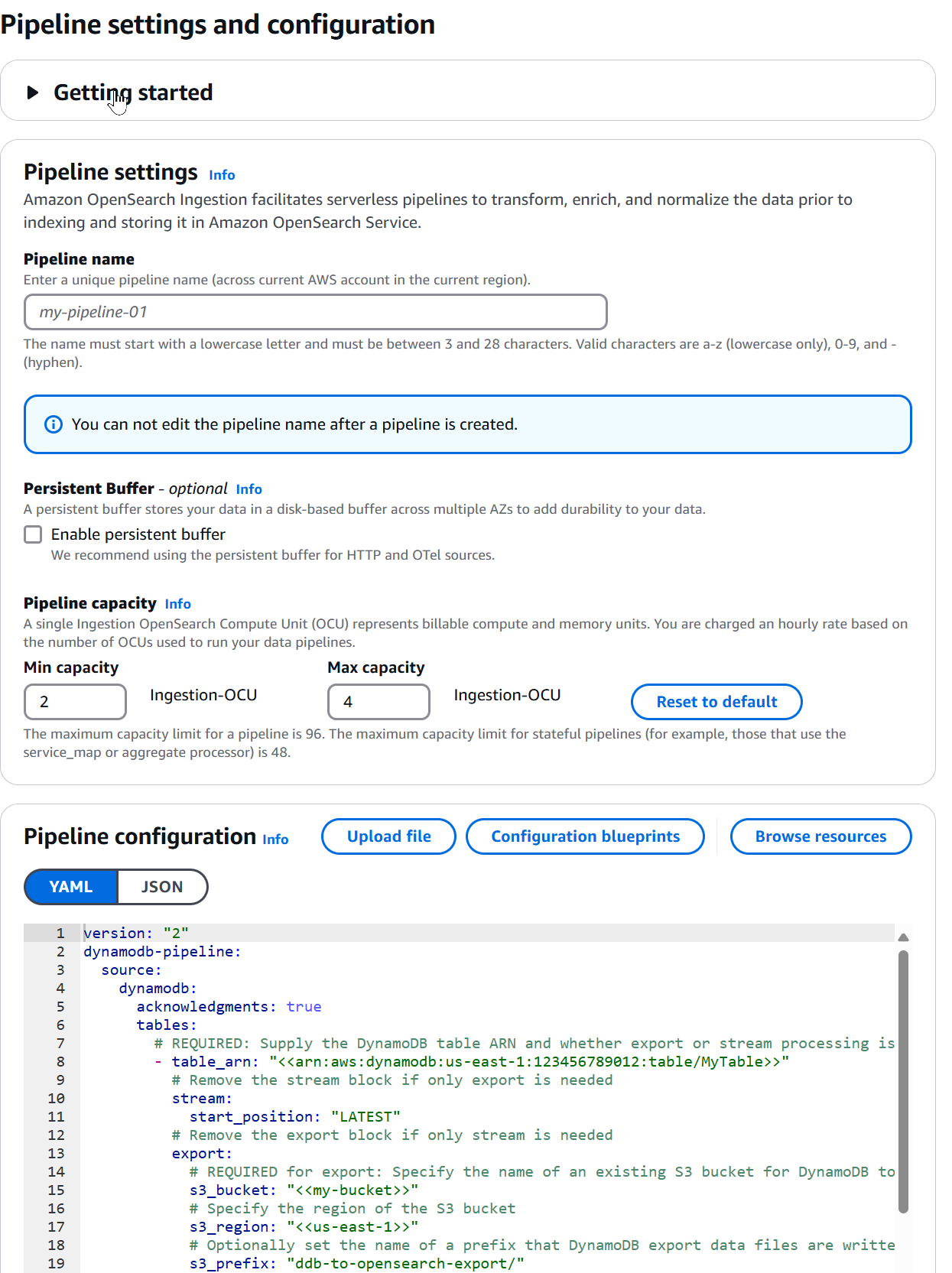
The pipeline configuration consists of two parts - the Source and the Sink.
version: "2"
dynamodb-pipeline:
source:
...
sink:
...The source sets up the configuration details for the DynamoDB, S3 Export, and associated roles and regions.
Similarly the sink sets up the configuration details for OpenSearch, the index and how to map the data from DynamoDB into the index.
Let's explore each of these configurations.
Configuring DynamoDB Zero ETL Pipeline Source Configuration
For the source, we must specify the DynamoDB Table arn, the S3 bucket details to store the temporary PITR export data from DynamoDB, and the AWS Role IAM that provides access to both DynamoDB and S3.
Below, I am using the DynamoDB table Event and an S3 bucket event-data-ingestion.
source:
dynamodb:
acknowledgments: true
tables:
- table_arn: "arn:aws:dynamodb:ap-southeast-2:123456789012:table/Event"
stream:
start_position: "LATEST"
export:
s3_bucket: "event-data-ingestion"
s3_region: "ap-southeast-2"
s3_prefix: "ddb-to-opensearch-export/"
aws:
sts_role_arn: "arn:aws:iam::123456789012:role/event-pipeline-etl-role"
region: "ap-southeast-2"I've also specified the Role ARN to use for the pipeline. More on the IAM Role setup below.
Configuring DynamoDB Zero ETL Pipeline Sink Configuration
The sink configuration section sets up the OpenSearch details - the host URL, the index name, the id for the index item (derived from the Dynamodb item using its primary key), etc.
sink:
- opensearch:
hosts: [ "https://search-myyoutubedoman-ocn5kk4bjel4ba4m2chmyt4c5a.ap-southeast-2.es.amazonaws.com" ]
index: "event-data-index"
index_type: custom
document_id: "${getMetadata(\"primary_key\")}"
action: "${getMetadata(\"opensearch_action\")}"
document_version: "${getMetadata(\"document_version\")}"
document_version_type: "external"
flush_timeout: -1
aws:
sts_role_arn: "arn:aws:iam::123456789012:role/event-pipeline-etl-role"
region: "ap-southeast-2"
serverless: false
dlq:
s3:
bucket: "event-data-ingestion"
key_path_prefix: "dynamodb-pipeline/dlq"
region: "ap-southeast-2"
sts_role_arn: "arn:aws:iam::123456789012:role/event-pipeline-etl-role"We can also set dlq configuration element, which points to an S3 bucket, where any items that throw an error during the sync will be moved.
Configuring DynamoDB Zero ETL Pipeline IAM Role
To set up the IAM Role, I created a new Role under IAM → Roles and added two inline policies.
The source's IAM Role requires access to the DynamoDB Table to export data, read data from the DynamoDB streams, and write this data into the S3 bucket.
You can find more details on the IAM Role configuration for the source here.
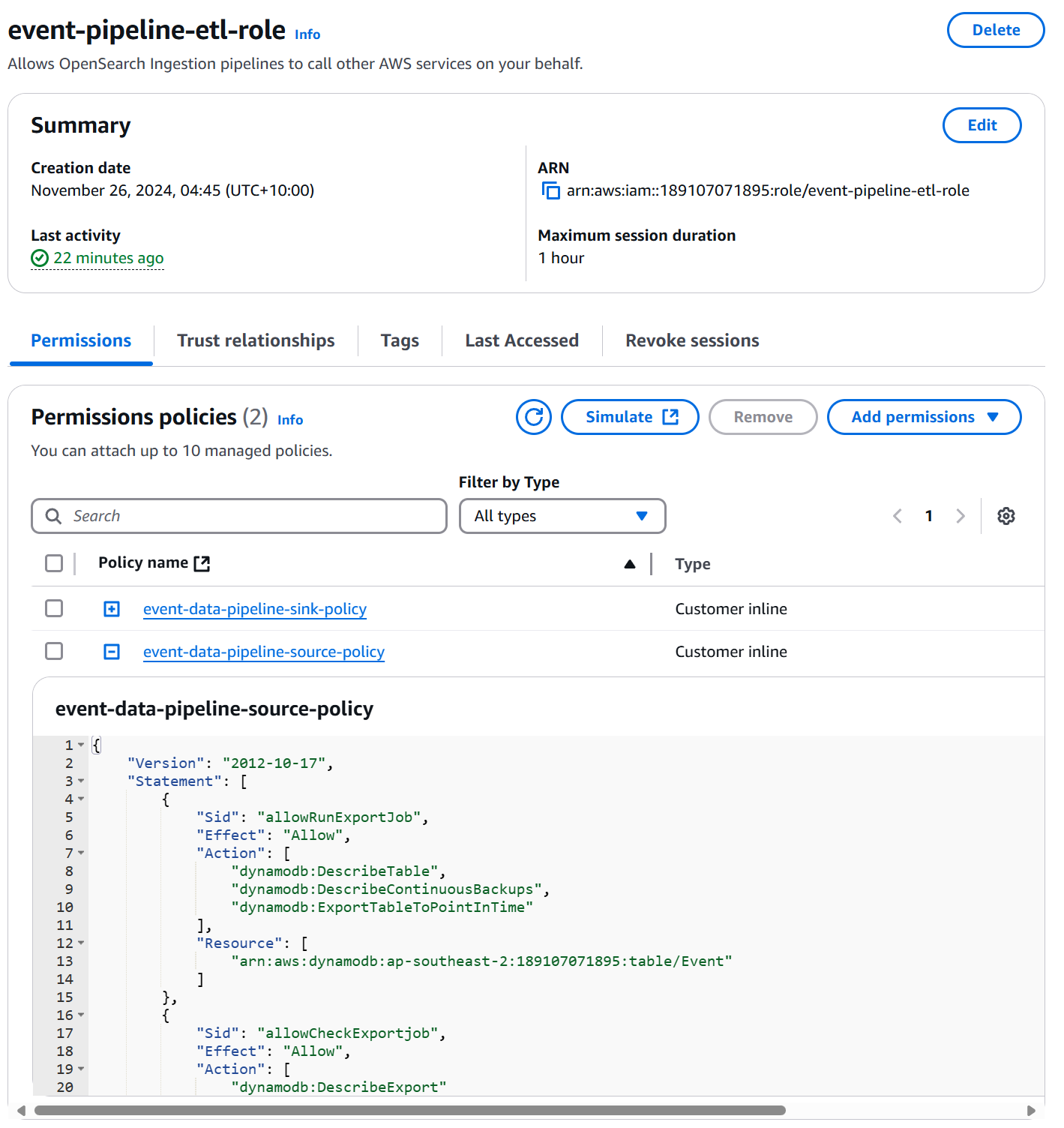
The IAM role also requires access to connect to OpenSeach and write data. The configuration for the sink role is more detailed here.
Here's the full policy I used
Here's the full policy I used
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "es:DescribeDomain",
"Resource": "arn:aws:es:ap-southeast-2:123456789012:domain/"
},
{
"Effect": "Allow",
"Action": "es:ESHttp",
"Resource": "arn:aws:es:ap-southeast-2:123456789012:domain/myyoutubedoman/"
},
{
"Sid": "allowRunExportJob",
"Effect": "Allow",
"Action": [
"dynamodb:DescribeTable",
"dynamodb:DescribeContinuousBackups",
"dynamodb:ExportTableToPointInTime"
],
"Resource": [
"arn:aws:dynamodb:ap-southeast-2:123456789012:table/Event"
]
},
{
"Sid": "allowCheckExportjob",
"Effect": "Allow",
"Action": [
"dynamodb:DescribeExport"
],
"Resource": [
"arn:aws:dynamodb:ap-southeast-2:123456789012:table/Event/export/"
]
},
{
"Sid": "allowReadFromStream",
"Effect": "Allow",
"Action": [
"dynamodb:DescribeStream",
"dynamodb:GetRecords",
"dynamodb:GetShardIterator"
],
"Resource": [
"arn:aws:dynamodb:ap-southeast-2:123456789012:table/Event/stream/"
]
},
{
"Sid": "allowReadAndWriteToS3ForExport",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:AbortMultipartUpload",
"s3:PutObject",
"s3:PutObjectAcl"
],
"Resource": [
"arn:aws:s3:::event-data-ingestion/"
]
}
]
}
Once the pipeline configuration is done - click Create - which will create and setup the data ingestion pipeline.
For the IAM role to be able to add data to Amazon OpenSeach ou also need to make sure to Map the role to the required Security role in Amazon OpenSeach.
For this navigate to the Amazon OpenSearch dashboard, under Security → Roles → all_access → Map user, specify the Role ARN as the Backend role. (as shown below).
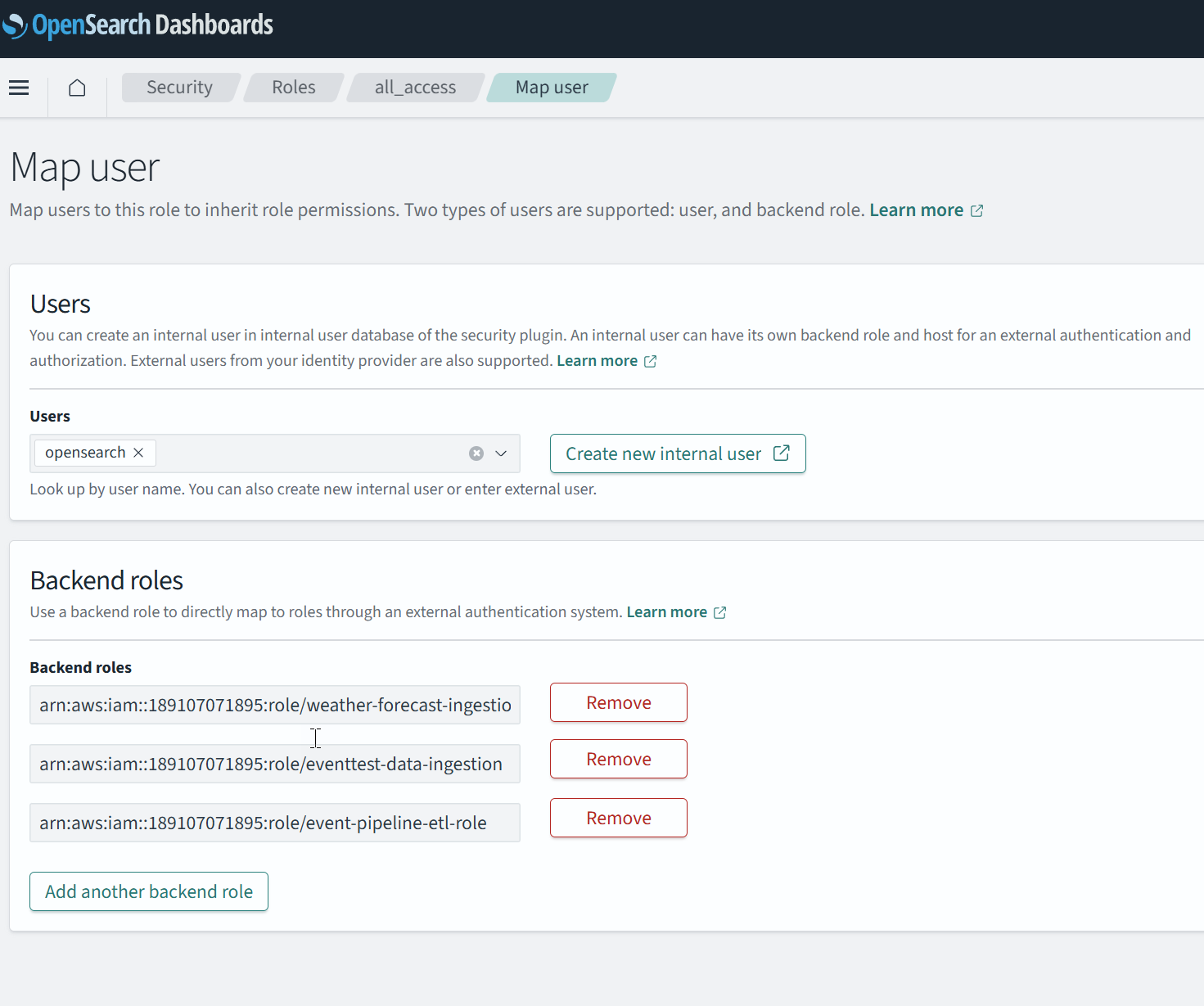
You can restrict to these absolute required permissions if required, which mean you would be using a different role instead of all_access.
Once the pipeline configuration is up and running, you should be able to see your DynamoDB data in Amazon OpenSearch.
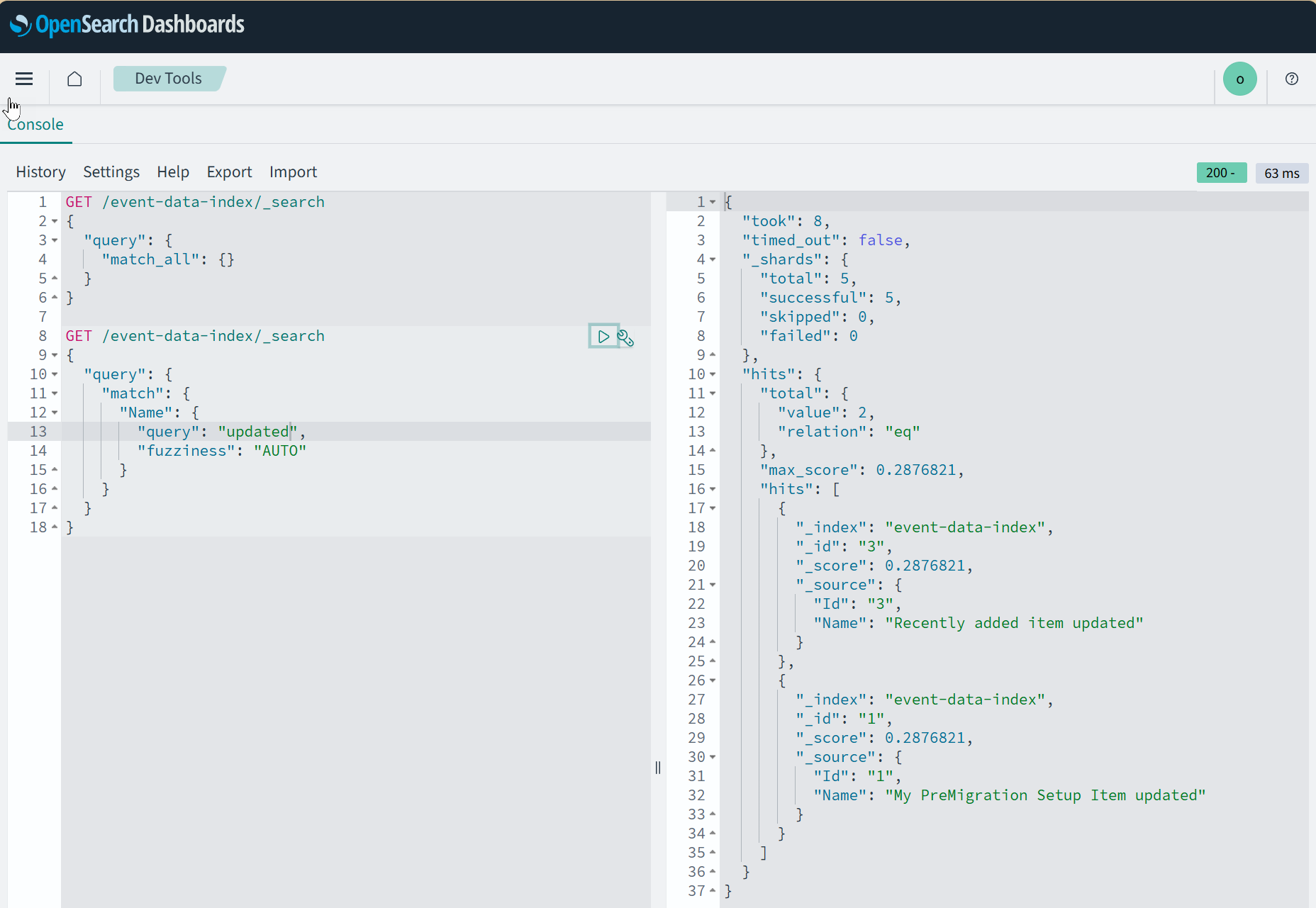
The configuration also supports transforming the data from DynamoDB before ingesting it into OpenSearch.
I will cover this in a different article.
Have a great day 👋

Rahul Nath Newsletter
Join the newsletter to receive the latest updates in your inbox.


{kind=link}