
Amazon S3 and AWS Lambda Triggers in .NET
Amazon S3 raises event notifications when Objects are created and modified. Learn how to use this to trigger Lambda Functions in .NET and the different configuration associated with processing the notification messages.
Table of Contents
This article is sponsored by AWS and is part of my AWS Series.
Amazon Simple Storage Service (S3) is an object storage service that allows you to store any data.
Any time an object is created or modified in S3, it raises event notifications. We can use these notifications in specific scenarios to perform additional business logic or application processing.
For example - When a user uploads a profile picture image, we can store the file in S3 storage and use event notifications when the file is written to process them as thumbnails and other formats. We can also use event notifications to process large data files uploaded for bulk processing.
You will learn:
- Build and set up a Lambda Function to handle S3 event notification.
- Different Lambda trigger configurations.
- Exception handling when processing S3 Event Notifications.

S3 Event Notification Types and Destinations
Amazon S3 supports notifications for different types and destinations to publish these events. When configuring event notification triggers, you can specify the event types and the destination for the events.
Notification Types
Below are the Notification Types supported by Amazon S3.
- s3:TestEvent → Test notification event created when notification is enabled on S3
- s3:ObjectCreated: → Object created or updated events. The * can also be replaced by PUT, POST, or COPY if you want to listen to specific operations on S3.
- s3:ObjectRemoved: → Objects are removed from S3. The * can be replaced by Delete or DeleteMarkerCreated.
Event Destinations
Amazon S3 can send event notifications to different destinations. Amazon SNS, Amazon SQS, AWS Lambda, and Amazon EventBridge are currently supported destinations. When setting up the destinations, we can specify the notification types to be sent to the particular destination.
Build and Deploy .NET Lambda Function
AWS Lambda is Amazon’s answer to serverless computing services. It allows running code with zero administration of the infrastructure that the code is running on.
Make sure to install the AWS Toolkit (Visual Studio, Rider, VS Code) and set up Credentials for the local development environment. This helps you quickly develop a .NET application on the AWS infrastructure and deploy them quickly to your AWS Accounts.

With the AWS Toolkit installed, select the AWS Lambda Lambda Project template from the new project template and choose the S3 blueprint. This creates an AWS Lambda function template project with a Function.cs class with everything required to handle S3 events, as shown below.
public class Function
{
public async Task<string?> FunctionHandler(S3Event evnt, ILambdaContext context)
{
var s3Event = evnt.Records?[0].S3;
if(s3Event == null)
{
return null;
}
try
{
var response = await this.S3Client.GetObjectMetadataAsync(s3Event.Bucket.Name, s3Event.Object.Key);
context.Logger.LogInformation(response.Headers.ContentType);
return response.Headers.ContentType;
}
catch(Exception e)
{
context.Logger.LogInformation($"Error getting object {s3Event.Object.Key} from bucket {s3Event.Bucket.Name}. Make sure they exist and your bucket is in the same region as this function.");
context.Logger.log information(e.Message);
context.Logger.log information(e.StackTrace);
throw;
}
}
}
The S3Event class represents the S3 event notification and contains the S3 object information and associated metadata for the event.
Deploy Lambda Function
To publish the Lambda function to the AWS account, you can use the Publish to AWS Lambda option that the AWS Toolkit provides. You can directly publish the new lambda function with your development environment connected to your AWS account.
I prefer to set up an automated build/deploy pipeline to publish to your AWS Account for real-world applications. Check out the below for an example of how to set up a Lambda Function deployment pipeline from GitHub Actions.
Setting Up S3 Notification and Lambda Trigger
With the Lambda Function deployed, we can set up the function to trigger on S3 event notifications.
You can do this under the Lambda Function or the S3 Bucket for which you want to listen to the notifications.
Under the Lambda Function, navigate to Configuration → Triggers and choose the ‘Add Tigger’ button (as shown below).
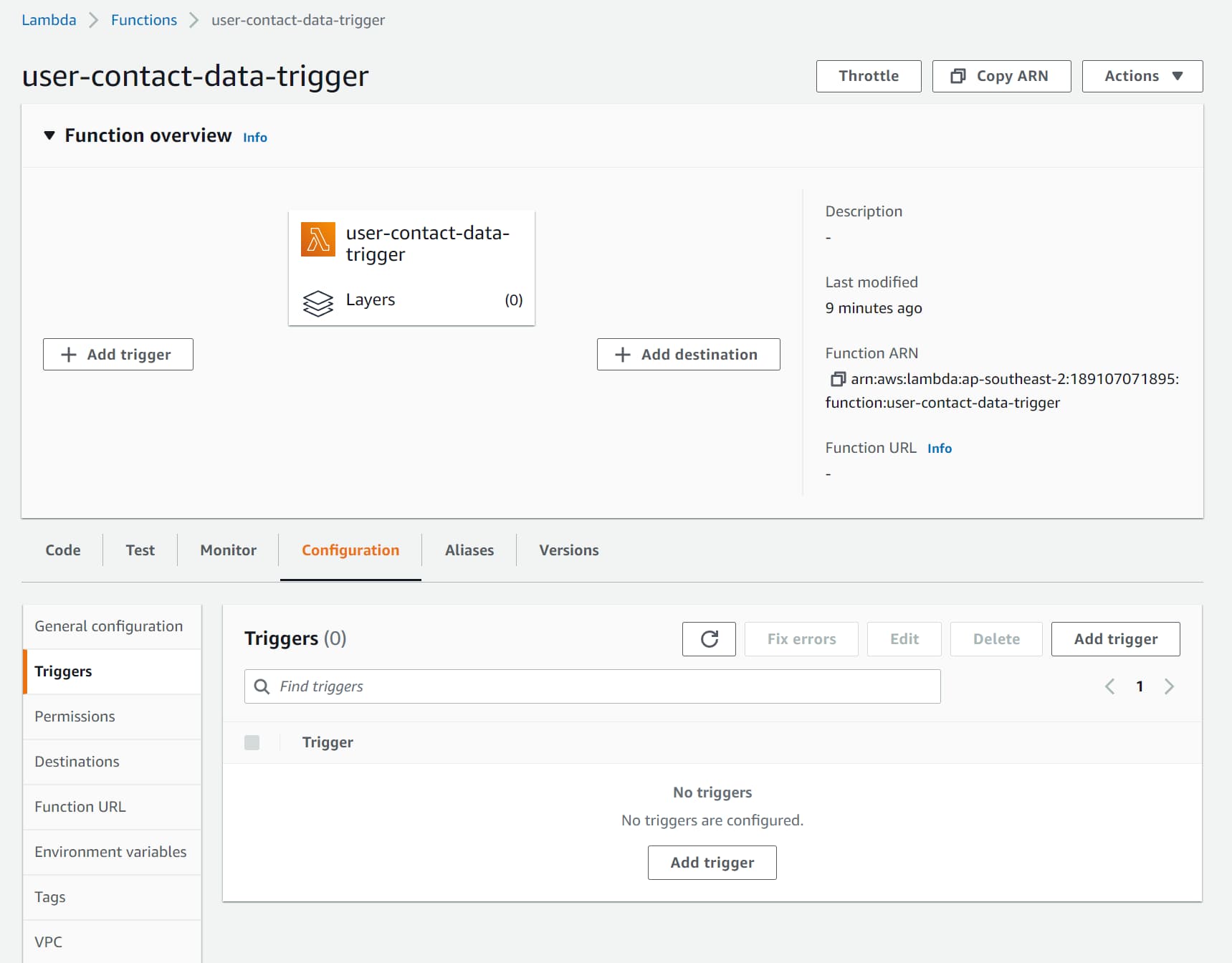
Add Trigger from the Lambda Function under Configuration → Triggers. This allows you to choose different sources for the Lambda Trigger, and one of them is S3.
It prompts us to select the Source of the trigger. Select S3 and specify the source Bucket (user-contact-data in this case).
Select the event types that you want to trigger Lambda Function.
Below I’ve selected ‘All object create events, which will trigger on create, update, copy, and multipart uploads of objects to the S3.
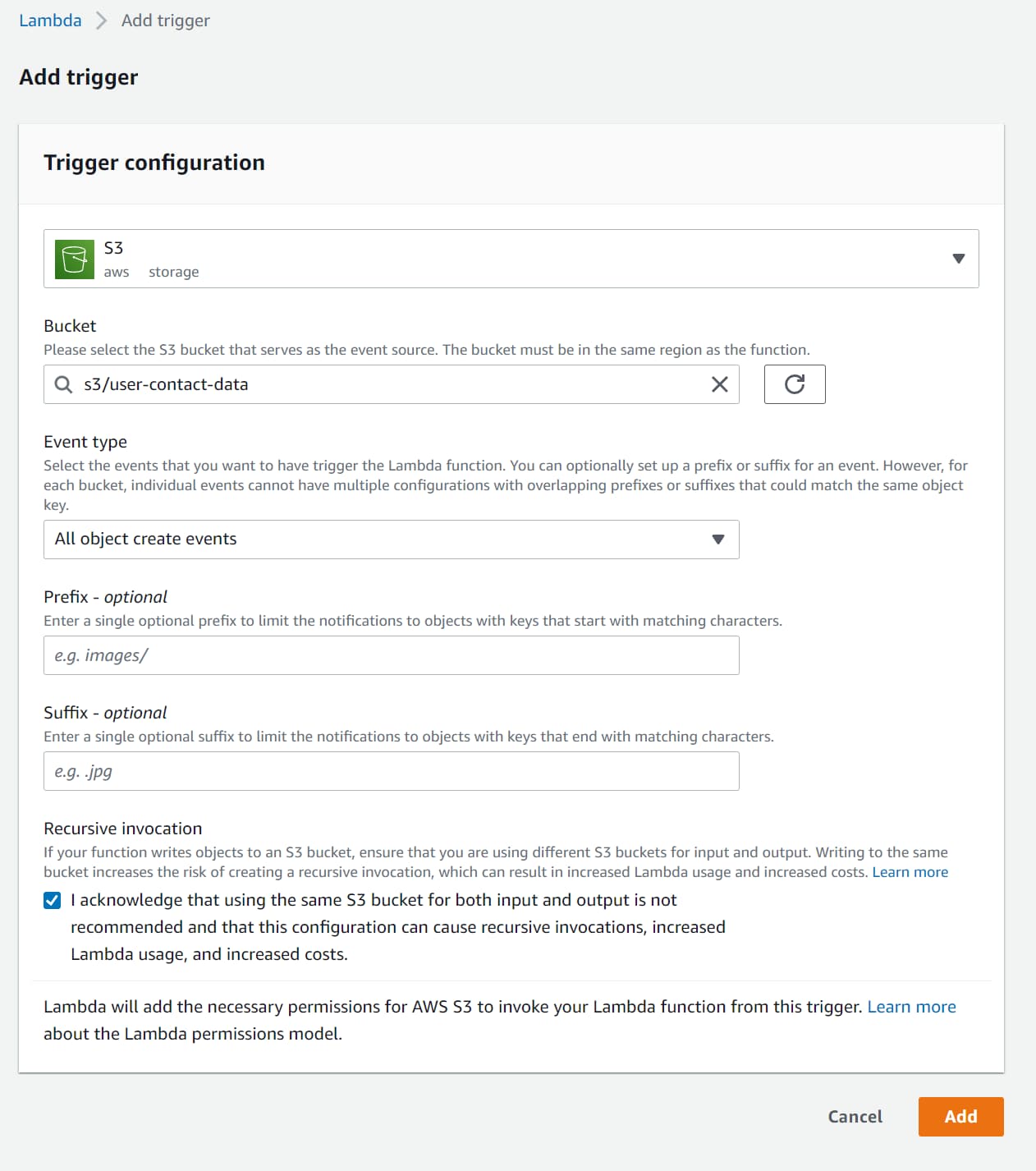
When adding the Trigger, the S3 is permitted to invoke the Lambda Function. This is required so that any time an S3 notification occurs, it can invoke the Lambda Function with the Object details.
The permission added can be seen under the ‘Resource-based policy’ section under the Lambda Function Configuration → Permissions, as shown below.
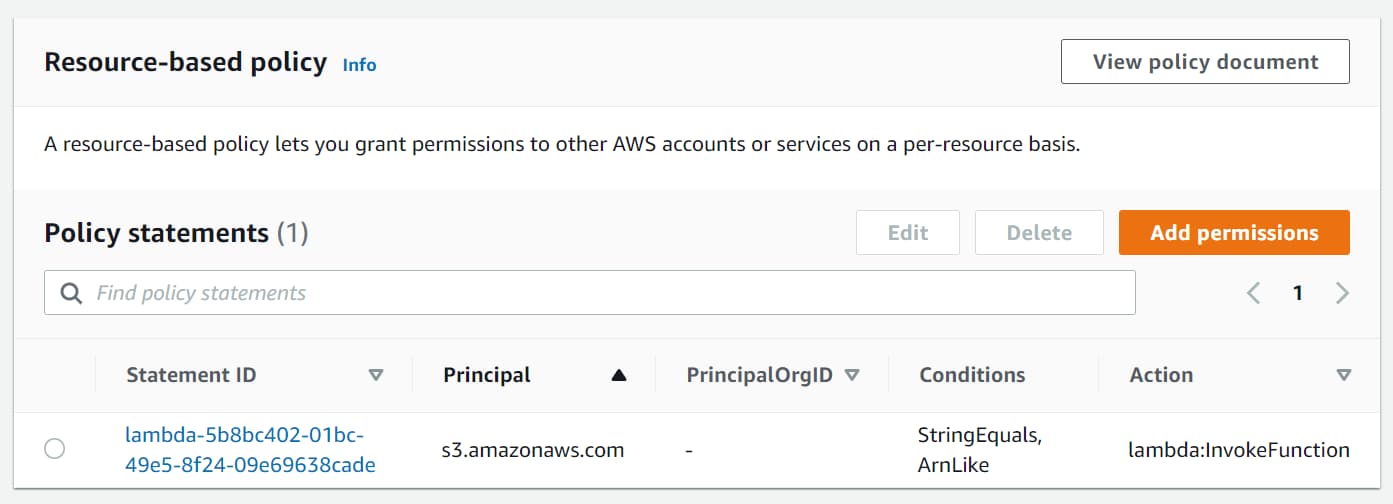
IAM Policies
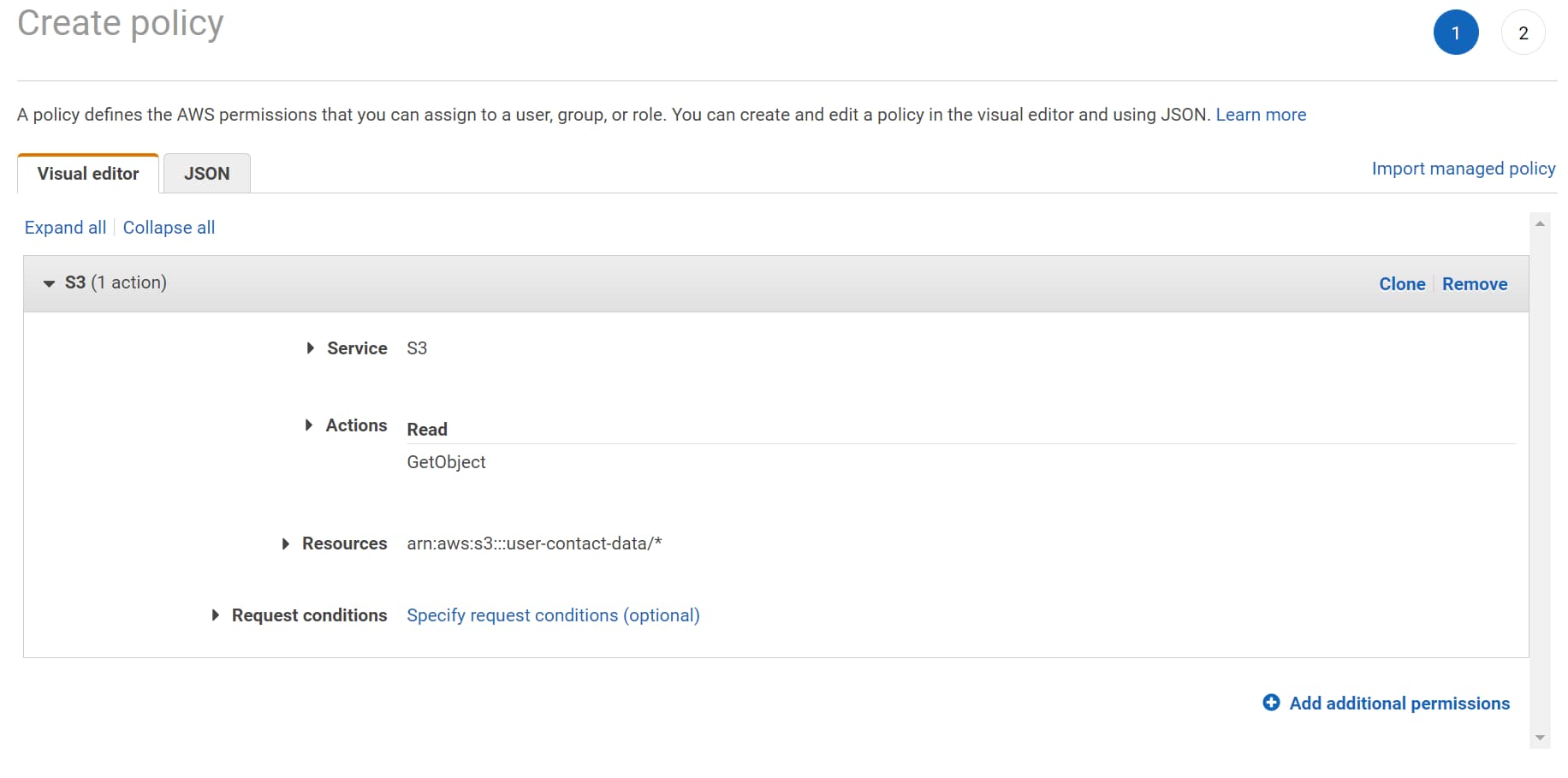
Since the Lambda Function uses the AmazonS3Client to read the Object metadata on processing the event notification, we need to ensure the Lambda function has the appropriate permissions to talk to S3.
For this, we can edit Lambda’s IAM Role and add an inline policy with the GetObject read permission on the S3 storage.
Testing Integration
Upload a new file to the S3 Bucket to test the end-to-end integration. This triggers an S3 notification, which is sent to the Lambda Function.
On receiving the notification, Lambda functions use the AmazonS3Client to get the newly added object's metadata and log it to CloudWatch.
If required, you can update the Function handler code to read the file's contents, as shown below.
var file = await this.S3Client.GetObjectAsync(s3Event.Bucket.Name, s3Event.Object.Key);
using var reader = new StreamReader(file.ResponseStream);
var fileContents = await reader.ReadToEndAsync();
context.Logger.LogInformation(fileContents);
The file contents can be used for business processing or other application-related functionality in a real-world scenario.
Lambda Trigger Configuration
The Lambda Configuration supports two additional configuration properties - Prefix and Suffix. Both are optional.
- Prefix → Limits the notifications to objects with names starting with the specified characters.
- Suffix → Limits the notifications to objects with names ending with the specified characters.

In the above screenshot, I have Prefix as ‘unprocessed/’, which means only S3 Objects uploaded to the folder unprocessed, will trigger a notification of the Lambda Function.
Specifying the Prefix and Suffix is particularly useful if you are reading/writing back to the same S3 Bucket from the same Lambda Function. This otherwise would cause a recursive invocation of the Lambda Function. Using Prefix, you can trigger the Lambda Function only when a file is changed under a specific filter (being under the unprocessed folder). You can write back the new file to a different folder that does not fall under the original filter condition.
E.g., Suppose we are processing images using the Lambda Function. When they are uploaded to the ‘unprocessed’ folder, you can write back the processed image to a different folder (’processed’) so that it will not trigger the Lambda function again.
S3 Notification and Exception Handling
Amazon S3 invokes Lambda Function asynchronously. This means the Lambda Function does not wait for a response from the Function code. S3 hands off the notification message, and Lambda is responsible for the rest.
As long as the messages get processed successfully, things go okay. But it’s when messages fail to process (which can happen for various reasons), we need to do additional configuration.
Simulating Exception in .NET Lambda
To simulate an exception in processing in our simple S3 Lambda Handler, let’s add a condition on the S3 Object name.
If the file name contains the word ‘Exception,’ the function handler will throw an exception. This makes it easy to simulate an exception condition.
public async Task<string?> FunctionHandler(S3Event event, ILambdaContext context)
{
var s3Event = evnt.Records?[0].S3;
if (s3Event == null)
{
return null;
}
if (s3Event.Object.Key.Contains("Exception"))
throw new Exception($"Exception processing file {s3Event.Object.Key}");
... //Remaining Processing
}
If we upload a file with a name that contains ‘Exception’, the Lambda function will fail to process the notification message.
Default Retry Behaviour
By default, Lambda retires the message two times on an exception when processing the message asynchronously.
This is configured under Configuration → Asynchronous invocation section.
It also specified the maximum age of the event as 6 hours, which means the message will be discarded after that time if not processed.
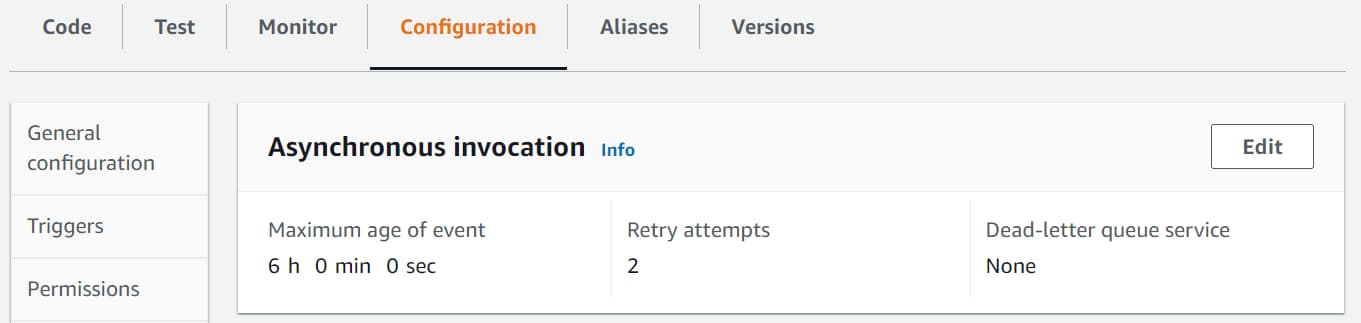
So for an Object uploaded with ‘Exception’ in the name, we will see the message processed by the Lambda Function 3 times - 1 on the notification + 2 retries. The first retry is after 1 minute of the original notification and then 2 minutes after the first retry.
If the notification's processing errors are due to transient errors (which go away with time), it might get processed the second time. But for errors that aren’t transient (like in our case, since it will always error if the file name has the word ‘Exception’), it will retry two times and then be discarded. The notification will be lost.
Lambda Asynchronous Invocation Configuration
To prevent notifications from being lost after two retries, we can update the Asynchronous configuration and specify a Dead-letter queue (DLQ).
Any unprocessed messages after the specified number of Retry attempts (0, 1, or 2) will be automatically moved to the specified Dead Letter Queue.
The DLQ can be Amazon SQS or Amazon SNS. Below I have configured it to be an SQS.
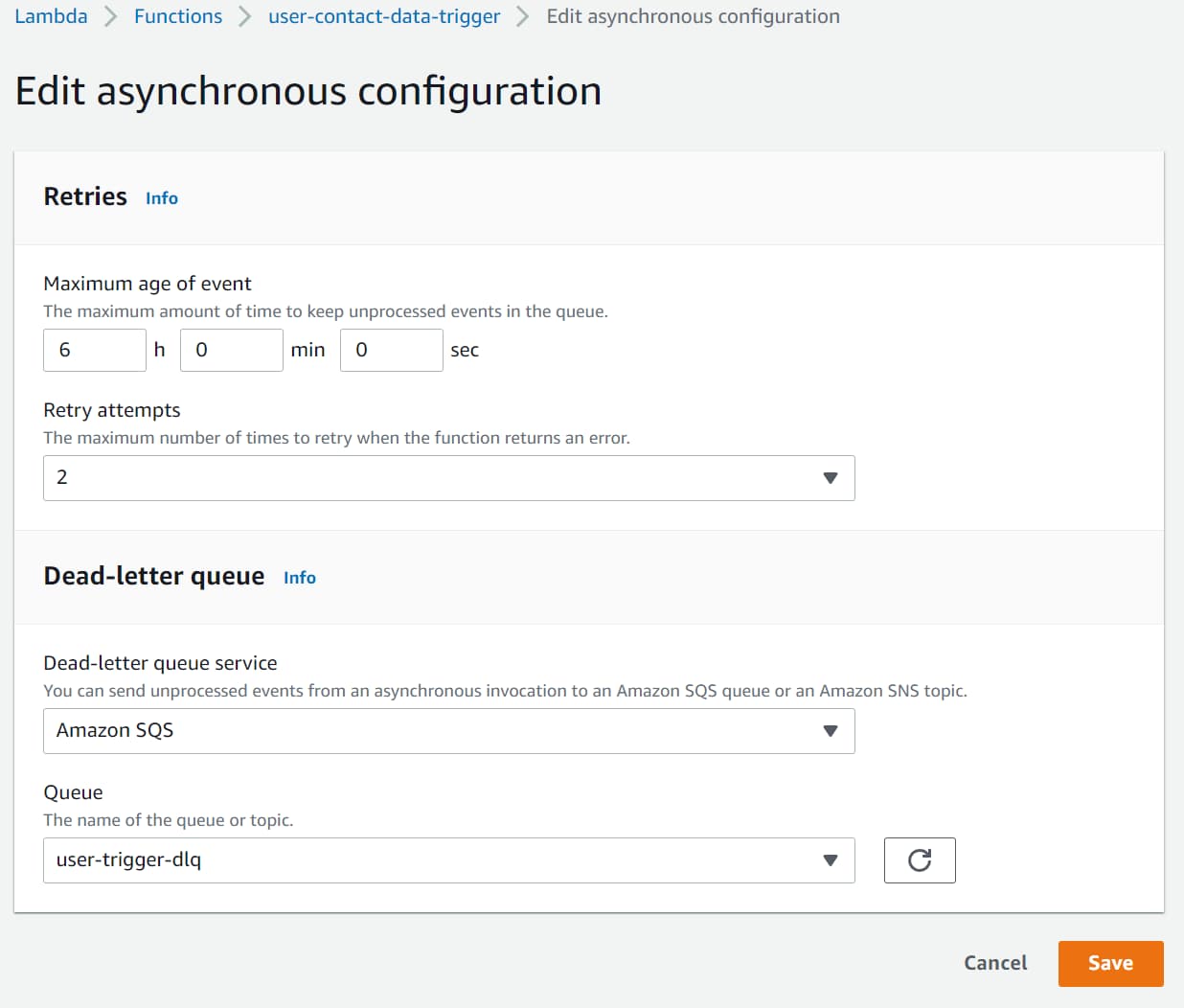
Any notifications that have already been discarded before updating this configuration are permanently lost. New notifications that cannot be processed after two retries will be moved to the SQS.
Based on the message and your business needs, you can reprocess these messages by addressing the error in processing.
I hope this helps you to understand and set up Lambda Triggers based on S3 Object notifications.

Rahul Nath Newsletter
Join the newsletter to receive the latest updates in your inbox.


{kind=link}