
Amazon S3 For the .NET Developer: How to Easily Get Started
Learn how to get started with Amazon S3 from a .NET Core application. We will learn how to store and retrieve data from the storage, important concepts to be aware of while using S3.
Table of Contents
This article is sponsored by AWS and is part of my AWS Series.
Amazon Simple Storage Service (S3) is an object storage service that provides a scalable and secure storage infrastructure. You can store any type of data in S3, which makes it suitable for a wider variety of use cases, including using it as a NO SQL Database.
While Amazon S3 allows interactions through the UI console, it’s more useful when applications can directly talk to it and use it to manage and store data.
In this blog post, let’s look at how to start using Amazon S3 from a .NET application. We will learn how to store and retrieve data from the storage, essential concepts to be aware of while using S3.
Basic Concepts
When using S3, two standard terms that you will come across often are Buckets and Objects.
Bucket
A Bucket is a container for Objects and is required to start adding Objects to S3 storage. The default Service Quota allows the creation of up to 100 buckets. This is a soft limit and can be increased on request. Buckets are identified using a name that must be globally unique across all AWS and not specific to your account. It’s generally good to prefix names with your application/organization names to make names more unique. Bucket naming must also follow specific naming rules.
Objects
Any data/file stored in S3 is referred to as an Object. It is the fundamental entity stored in S3. An object consists of the data and associated metadata. The Object's name is referred to as Key and uniquely identifies it within a bucket.
Amazon S3 & .NET
Amazon S3 allows programmatic access via REST API and provides SDKs for popular languages.
To get started using the SDK, let’s create a sample application. The sample application I am using is a default ASP NET Core Web API (.NET Core 6) template created using Visual Studio. It has a WeatherForecastController with a GET endpoint by default.
For .NET, the AWSSDK.S3 NuGet package can be used to connect and interact with S3. You can find the source code for the library here. Install the NuGet package.
To import weather data information into our application, let’s add a new POST endpoint to upload weather data files (as IFormFile). As we upload the files, it’s good to persist these files for later background processing, especially if these are time-consuming tasks.
We can store these files in Amazon S3 to process them later in a background process.
Create Bucket
To store the files in Amazon S3, we need to create a Bucket to hold our files.
You can create Buckets - once-off from the console UI, from the application, using CloudFormation templates (or IAC) through your build deploy pipeline, etc.
In this case, let’s see how we can create a bucket using .NET code.
Using the AmazonS3Client from the NuGet package, we can connect to Amazon S3 and perform various functions.
I use the Shared AWS Credentials stored on my local machine to authenticate with my AWS account. When deployed to AWS, it will use the IAM permissions configured for the application (if running on AWS itself).
Using the PutBucketAsync method on the S3 Client, we can pass a PutBucketRequest specifying the BucketName and the region for the Bucket.
private const string BucketName = "weather-forecast-rahul-youtube";
[HttpPost]
public async Task Post(IFormFile file)
{
var s3client = new AmazonS3Client();
var bucketRequest = new PutBucketRequest()
{
BucketName = BucketName,
UseClientRegion = true
};
await s3Client.PutBucketAsync(bucketRequest);
}
The above code creates a new Bucket, provided no bucket exists with the same BucketName.
The above POST endpoint will error out the second time it’s run since the Bucket exists after the first run. You cannot create a Bucket again with the same name.
So any time you are creating a Bucket in code, it’s a good idea to check if a Bucket already exists with the same name.
The AmazonS3Util class as part of the same NuGet package provides the DoesS3BucketExistV2Async method to check if a BucketName already exists or not. Using that, we can conditionally create a new Bucket only if it does not already exist.
var bucketExists = await AmazonS3Util.DoesS3BucketExistV2Async(s3Client, BucketName);
if (!bucketExists)
{
// Create Bucket
}
Upload File
Objects are uploaded to S3 into a Bucket. The AmazonS3Client also provides methods to manage Objects.
The PutObjectAsync method takes a PutObjectRequest to upload a file to S3.
var objectRequest = new PutObjectRequest()
{
BucketName = BucketName,
Key = formFile.FileName,
InputStream = formFile.OpenReadStream()
};
var reponse = await s3Client.PutObjectAsync(objectRequest);
At the minimum, the request must contain the BucketName, Key, and data (InputStream) when uploading a new object. This creates a new Object in the specified Bucket.
The key uniquely identifies the Object in the Bucket and is required for all interactions with the specific Object.
Versioning
If you upload a new Object with the same key, it will overwrite the existing file. When creating Buckets, you can enable Versioning. In this case, any new Object uploaded with the same key will be added as the latest version of that Object. The old Object will still be available if you use the specific version identifier when getting the particular Object version.
Depending on your application and use cases, you can either overwrite the same file or append unique codes to the file name to ensure they don’t overwrite existing files. Prefixing with a DateTime stamp or a unique GUID or database identifiers etc., are items you can append to ensure file uniqueness.
Hierarchical Storage
Amazon S3 has a flat data structure. You have a Bucket, and within that, you have Objects with a key. However, you can introduce logical hierarchies by using the ‘/’ delimiter.
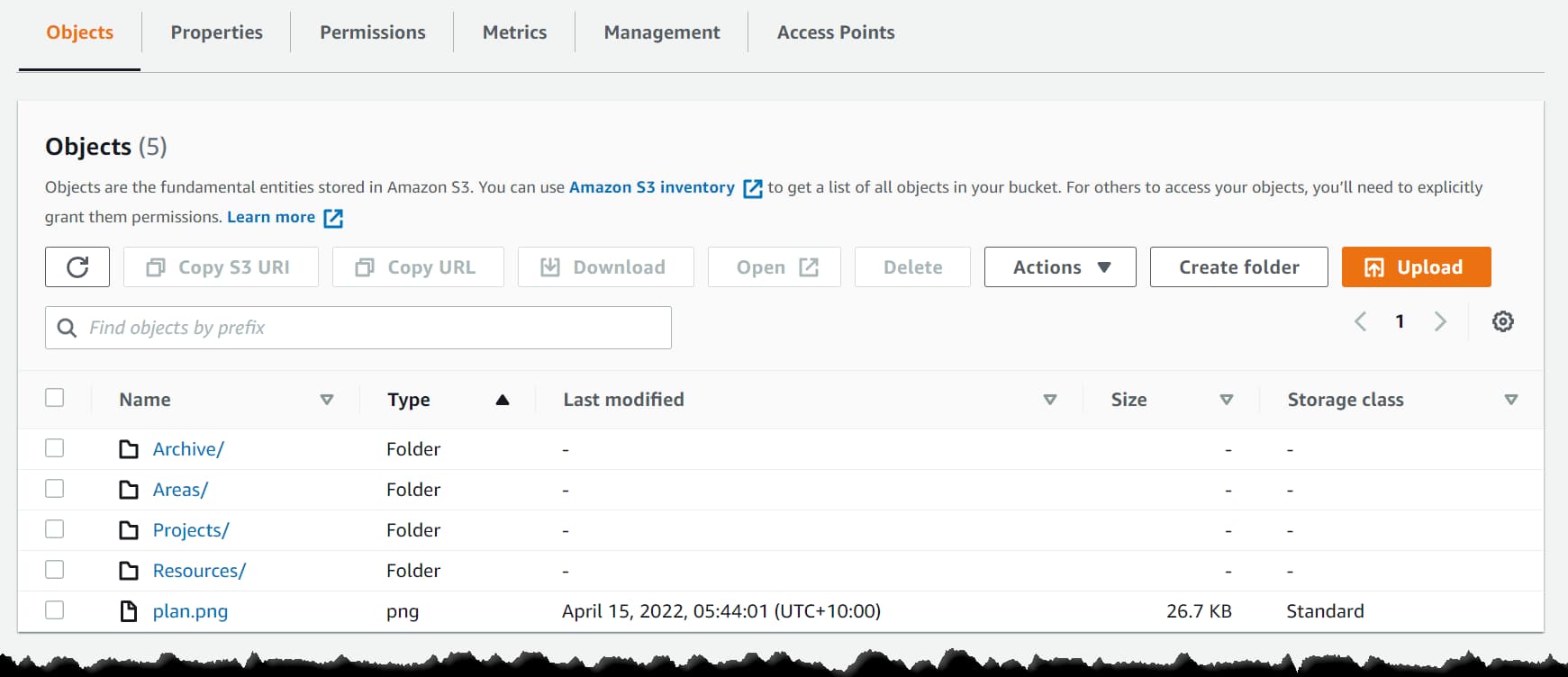
The AWS Console uses the delimiter in Object key names to group them as folders, as shown above. When creating files, make sure to prefix the name with the appropriate logical grouping followed by ‘/’. You can also do multi-level grouping, allowing folders inside folders (e.g., Projects/Amazon S3/VideoScript.txt).
Object Metadata
An Object uploaded to S3 also has associated metadata, which are sets of name-value pairs. There are two kinds of metadata
- System-defined metadata → These are properties maintained by Amazon itself. Within this, some can be modified only by Amazon, and some that the user can set.
Storage Class is an example of system-defined metadata that can be updated by a user as well. Storage Class, by default is set to S3 Standard, and it impacts the pricing for S3 usage. Based on the usage scenario and performance requirement, you can choose from the different storage classes available.
- User-defined metadata → Optional set of user-provided key value. It is useful to store additional information along with the Object in S3. User-defined metadata names must begin with "x-amz-meta-”.
User-defined metadata can be added from the AWS Console or when creating the Object in code, as shown below.
...
objectRequest.Metadata.Add("Test", "New Meta");
var reponse = await s3Client.PutObjectAsync(objectRequest);
Retrieving Files
Depending on your use case, you can retrieve single files or as a list.
Given an Object key name, the GetObjectAsync method takes in the Bucket name and the key to retrieve the file, as shown below.
[HttpGet("getFile", Name = "GetWeatherForecastFile")]
public async Task<IActionResult> GetFile(string fileName)
{
var s3client = new AmazonS3Client();
var file = await s3client.GetObjectAsync(BucketName, fileName);
return File(file.ResponseStream, file.Headers.ContentType);
}
The above code directly streams the content back to an API request. You can also download the contents to memory and process them if required. This is useful in machine-to-machine file-based processing scenarios.
using var reader = new StreamReader(file.ResponseStream);
var contents = await reader.ReadToEndAsync();
Amazon S3 also supports retrieving files in bulk. If you want to process all files under a given logical folder hierarchy, you can use the ListObjectsV2Async method.
var request = new ListObjectsV2Request()
{
BucketName = BucketName,
Prefix = prefix
};
var response= await client.ListObjectsV2Async(request);
Presigned URLs
By default, all Objects uploaded to S3 are private. Using Presigned URLs, you can share files in the Bucket. You can attach different policies to the URL generated based on which you can restrict access to the file.
var presignRequest = new GetPreSignedUrlRequest()
{
BucketName = BucketName,
Key = objectKey,
Expires = DateTime.UtcNow.AddSeconds(300),
};
var presignedUrlResponse= s3Client.GetPreSignedURL(presignRequest);
The above code generated a Presigned URL that expires in 300 seconds. Anyone with the URL can access the Object in that Bucket during that time.
Delete Object
To delete an existing Object, we only need the key and the Bucket name. Using the DeleteObjectAsync method, we can delete an Object from the Bucket.
[HttpDelete]
public async void Delete(string fileName)
{
var response = await s3Client.DeleteObjectAsync(BucketName, fileName);
}
To protect against accidental deletes or to keep backups, you can enable Versioning on the Bucket. When versioned deleting an Object is only a soft delete, you can retrieve the Object using the specific version identifier.
Dependency Injection
To inject the AmazonS3Client into our class constructor, we must first register it in our Program.cs class. The AWSSDK.Extensions.NETCore.Setup NuGet package provides extensions methods to register AWS Service classes.
builder.Services.AddAWSService<IAmazonS3>();
With the IAmazonS3 interface registered in the Service Collection, we can inject it into our class via the constructor, as shown below.
public WeatherForecastController(
IAmazonS3 s3Client,
ILogger<WeatherForecastController> logger)
{
this.s3Client = s3Client;
this.logger = logger;
}
You can use the injected s3Clientinstance in all the functions instead of creating a new instance of AmazonS3Client every time.
I hope this helps you to get started with Amazon S3 from a .NET application.
Photo by Lia Trevarthen on Unsplash

Rahul Nath Newsletter
Join the newsletter to receive the latest updates in your inbox.


{kind=link}