Generating a Large PDF from Website Contents - HTML to PDF, Bookmarks and Handling Empty Pages
Dynamically generate a PDF file for a CMS Website.
Table of Contents
Posts in this series
- Generating a Large PDF from Website Contents
- HTML to PDF, Bookmarks and Handling Empty Pages
- Merging PDF Files
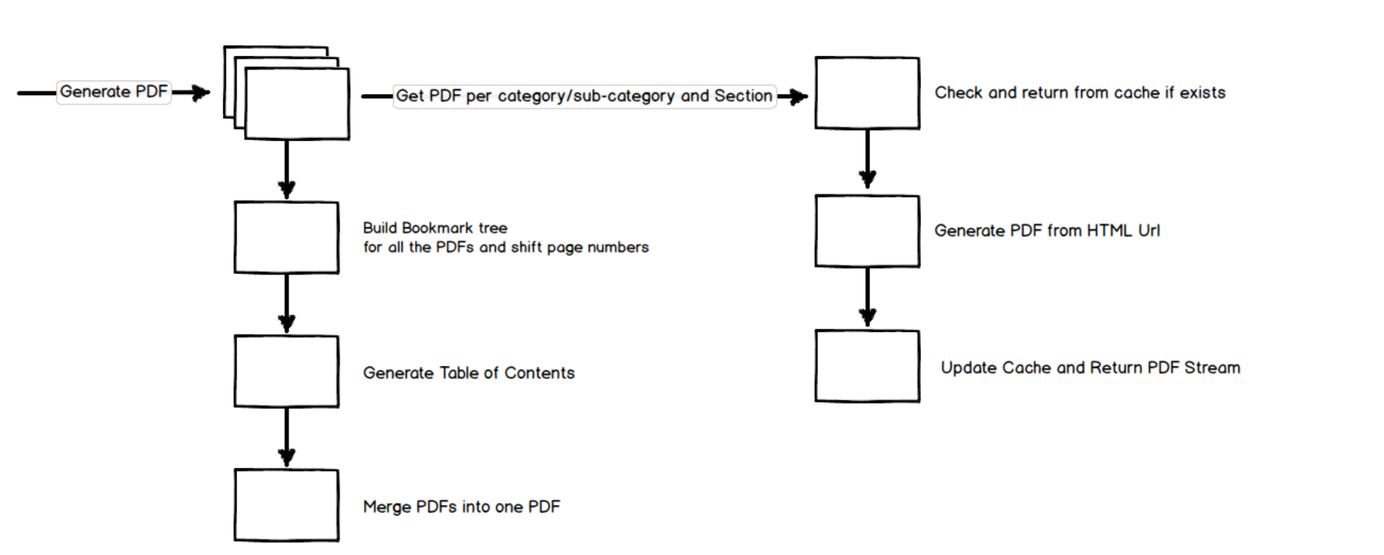
In the previous post, Generating a Large PDF from Website Contents we saw from a high level the approach taken to generate PDF files from a Content Management System (CMS) website. In this post, we will delve further into the details of each of those areas.
HTML To PDF
There are a lot of libraries and services that support converting HTML to PDF. We chose this mechanism mainly for keeping the content formatting simple and reusable. Most of the PDF data was to be structured like the website content. This means we can reuse (read copy/paste) the HTML styling for the PDF content as well.
We used Essential Objects HTML to PDF Converter library. Our website is hosted as an Azure Web App and the Essential Objects library does not work in the Azure sandbox environment. The Azure Sandbox restriction affects most of the HTML to PDF libraries. The recommended approach to use those libraries is to host the PDF conversion logic on an Azure Virtual Machine, which is what we also ended up doing. Alternatively, you can choose to use one of the HTML to PDF hosted services.
The below code snippet is what you need to convert an HTML URL endpoint to PDF. It uses the HtmlToPdf class from the EO.Pdf Nuget package. The HtmlToPdfOptions specifies various conversion and formatting options. You can set margin space, common headers, footers, etc. for the generated PDF content. It also provides extensibility points in the PDF conversion pipeline.
public FileContentResult Convert(string url)
{
var pdfStream = new MemoryStream();
var pdfDocument = new PdfDocument();
var pdfOptions = this.GetPdfOptions();
var result = HtmlToPdf.ConvertUrl(url, pdfDocument, pdfOptions);
pdfDocument.Save(pdfStream);
return new FileContentResult(pdfStream.ToArray(), "application/pdf");
}
HTML Formatting Tip
_You might want to avoid content being split across multiple pages. E.g., images, charts, etc. In this cases, you can use the page-break-_ CSS property to adjust page breaks. Essentials objects honors the page-break-* settings and adjusts the content when converting into PDF.*
Bookmarks
A bookmark is a type of link with representative text in the Bookmarks panel in the navigation pane. Each bookmark goes to a different view or page in the document. Bookmarks are generated automatically during PDF creation from the table-of-contents entries of a document.
We generate a lot of small PDF files (per section and category/sub-category) and then merge them together to form the larger PDF. Each of the sections has one or more entries towards Table Of Contents (TOC). We decided to generate bookmarks first per each generated PDF. When merging the individual PDF, the bookmarks are merged first, and then the TOC is created from the full bookmark tree.
Bookmarks can be created automatically or manually using Essential Objects library. Most of the other libraries also provide similar functionality. Using the AutoBookmark property we can have bookmarks created automatically based on HTML header (H1-H6) elements. If this does not fit with your scenario, then you can create them manually. In our case, we insert hidden HTML tags to specify bookmarks. Bookmark hierarchy is represented using custom attributes as shown below.
<a class="bookmark" id="TOC_Category1" name="Category1">Category 1</a>
...
<a class="bookmark" id="TOC_Category1_Section1" name="Section1" tocParent="TOC_Category1"
>Section 1</a
>
...
<a class="bookmark" id="TOC_Category1_Section2" name="Section2" tocParent="TOC_Category1"
>Section 2</a
>
...
Once the PDF is created from the URL, we parse the HTML content for elements with bookmark class and manually add the bookmarks into the generated PDF. The GetElementsByClassName and the CreateBookmark methods help us to create bookmarks from the hidden HTML elements in the page.
{
...
var result = HtmlToPdf.ConvertUrl(url, pdfDocument, pdfOptions);
BuildBookmarkTree(pdfDocument, result);
pdfDocument.Save(pdfStream);
...
}
private static void BuildBookmarkTree(PdfDocument pdfDocument, HtmlToPdfResult htmlToPdfResult)
{
var bookmarkElements = htmlToPdfResult.HtmlDocument.GetElementsByClassName("bookmark");
foreach (var htmlElement in bookmarkElements)
{
var bookmark = htmlElement.CreateBookmark();
... // Custom logic to build the bookmark hierarchy
// based on custom attributes or whatever approach you choose.
pdfDocument.Bookmarks.Add(bookmark);
}
}
Handling Empty Pages
In our case, the content is from a CMS, and the user gets an option to select what categories/sub-categories and sections of data to be displayed in the generated PDF. At times it happens that some of the selected combinations might not have any data in the system. To avoid printing a blank page (or an error page) in the generated PDF, we can check the conversion result to check for the returned content. Whenever the content does not exists the HTML endpoint returns an EmptyResult class. At the PDF conversion side, you can check if the response is empty and accordingly perform your logic to ignore the generated PDF.
public static class HtmlToPdfResultExtensions
{
public static bool IsEmptyResponse(this HtmlToPdfResult htmlToPdfResult)
{
return htmlToPdfResult != null &&
htmlToPdfResult.HtmlDocument != null &&
htmlToPdfResult.HtmlDocument.Body != null &&
string.IsNullOrEmpty(htmlToPdfResult.HtmlDocument.Body.InnerText);
}
}
Once the individual PDF files are created for each of the section and category/subcategory combination, we can merge them together to generate the full PDF. We will see in the next post how to merge the bookmarks together along with shifting the PDF pages and generating Table of Contents from the bookmarks.

Rahul Nath Newsletter
Join the newsletter to receive the latest updates in your inbox.


{kind=link}